Apache Iceberg 簡介
一、簡介
本教學將討論Apache Iceberg ,這是當今大數據領域流行的開放表格式。
我們將透過開源發行版的實作範例來探索 Iceberg 的架構及其一些重要功能。
2. Apache Iceberg 的由來
Iceberg 是由 Ryan Blue 和 Dan Weeks 於 2017 年左右在 Netflix 發起的。 Hive 的關鍵問題之一是在缺乏穩定原子事務的情況下無法保證正確性。
Iceberg 的設計目標是解決這些問題並提供三個關鍵改進:
- 支援ACID事務,保證資料的正確性
- 透過允許檔案層級的細粒度操作來提高效能
- 簡化和混淆表維護
Iceberg 後來開源並貢獻給 Apache 基金會,並於 2020 年成為頂級專案。如今,大數據領域幾乎所有主要參與者都支援 Iceberg 表。
3. Apache Iceberg的架構
Iceberg 的關鍵架構決策之一是追蹤表格而不是目錄中的資料檔案的完整清單。這種方法有很多優點,例如更好的查詢效能。
這一切都發生在元資料層,**這是冰山架構中的三層之一:**
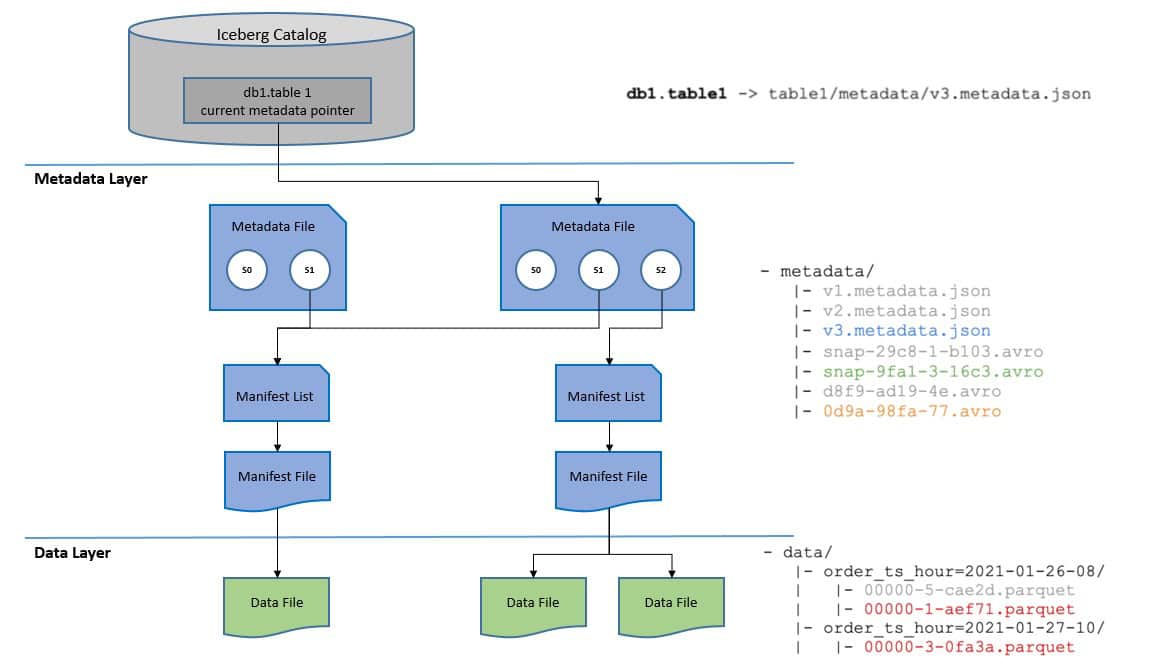
我們這裡有什麼?當從 Iceberg 讀取表格時,它會使用目前快照 (s1) 載入表格的元資料。如果我們更新此表,更新會使用新快照(s2)樂觀地建立一個新的元資料檔案。
然後,當前元資料指標的值會自動更新為指向這個新的元資料檔案。如果此更新所基於的快照 (s1) 不再是最新的,則必須中止寫入操作。
3.1.目錄層
目錄層有幾個功能,但最重要的是,它儲存當前元資料指標的位置。任何希望在 Iceberg 表上操作的計算引擎都必須存取目錄並取得當前的元資料指標。
目錄在更新目前元資料指標時也支援原子操作。這對於允許 Iceberg 表上的原子事務至關重要。
可用功能取決於我們使用的目錄。例如, Nessie提供了受 Git 啟發的資料版本控制。
3.2.元資料層
元資料層包含檔案的層次結構。頂部是一個元資料文件,用於儲存有關 Iceberg 表的元資料。它追蹤表的架構、分區配置、自訂屬性、快照以及哪個快照是當前快照。
元資料檔案指向一個清單列表,也就是清單檔案的列表。清單清單儲存有關組成快照的每個清單檔案的元數據,包括清單檔案的位置及其新增至哪個快照等資訊。
最後,清單檔案追蹤資料檔案並提供其他詳細資訊。清單檔案可讓 Iceberg 在檔案層級追蹤資料並包含可提高讀取操作的效率和效能的有用資訊。
3.3.資料層
資料層是資料檔案所在的位置,很可能位於 AWS S3 等雲端物件儲存服務中。 Iceberg 支援多種檔案格式,例如Apache Parquet 、 Apache Avro 和Apache ORC 。
Parquet 是 Iceberg 中儲存資料的預設檔案格式。它是一種面向列的資料檔案格式。其主要優點是高效率儲存。此外,它還具有高效能的壓縮和編碼方案。它還支援高效的資料訪問,特別是對於針對寬表中的特定列的查詢。
4. Apache Iceberg的重要特性
Apache Iceberg 提供事務一致性,允許多個應用程式在相同資料上協同工作。
它還具有快照、完整模式演化和隱藏分區等功能。
4.1.快照
Iceberg 表元資料維護一個快照日誌,該日誌表示應用於表的變更。
因此,快照表示表在某個時間點的狀態。 Iceberg支援讀者隔離和基於快照的時間旅行查詢。
對於快照生命週期管理,Iceberg 還支援分支和標籤,它們是對快照的命名引用:
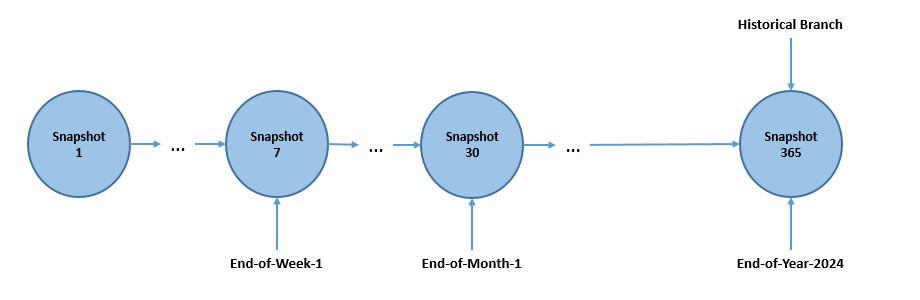
在這裡,我們將重要的快照標記為“週末”、“月末”和“年末”,以保留它們用於審計目的。它們的生命週期管理由分支和標籤級保留策略控制。
分支和標籤可以有多個用例**,例如保留重要的歷史快照以供審核**。
為表追蹤的架構在所有分支中都有效。但是,查詢標籤會使用快照的架構。
4.2.分割區
Iceberg透過在寫入時將相似的行分組來對資料進行分區。例如,它可以按日期對日誌事件進行分區,並將它們分組到具有相同事件日期的檔案中。這樣,它可以跳過沒有有用資料的其他日期的文件,並使查詢更快。
有趣的是,Iceberg 支援隱藏分區。這意味著它可以處理為表中的行生成分區值這一繁瑣且容易出錯的任務。使用者不需要知道表是如何分區的,並且分區佈局可以根據需要演變。
這是與 Hive 等早期表格式支援的分區的根本區別。對於 Hive,我們必須提供分區值。這將我們的工作查詢與表的分區方案聯繫起來,因此它無法在不破壞查詢的情況下進行更改。
4.3.演化
Iceberg 無縫支持表演化,並將其稱為「就地表演化」。例如,我們可以更改表格模式,即使是在巢狀結構中。此外,分區佈局也可以響應於資料量的變化而改變。
為了支援這一點,Iceberg 不需要重寫表格資料或遷移到新表。在幕後,Iceberg 僅透過執行元資料變更來執行模式演化。因此,不會重寫任何資料檔來執行更新。
我們也可以更新現有表格中的 Iceberg 表格分區。使用早期分區規範寫入的舊資料保持不變。但是,新資料是使用新分區規範寫入的。每個分區版本的元資料單獨保存。
5. 實作 Apache Iceberg
Apache Iceberg 被設計為開放社群標準。它是現代資料架構中的流行選擇,並且可以與許多資料工具互通。
在本節中,我們將透過使用Trino作為查詢引擎在Minio儲存上部署Iceberg REST 目錄來了解 Apache Iceberg 的實際應用。
5.1.安裝
我們將使用 Docker 映像來部署和連接 Minio、Iceberg REST 目錄和 Trino。最好有一個像Docker Desktop或 Podman 這樣的解決方案來完成這些安裝。
讓我們先在 Docker 中建立一個網路:
docker network create data-network本教學中的命令適用於 Windows 電腦。其他作業系統可能需要進行更改。
現在讓我們部署具有持久性儲存的 Minio (將主機目錄「data」掛載為磁碟區):
docker run --name minio --net data-network -p 9000:9000 -p 9001:9001 \
--volume .\data:/data quay.io/minio/minio:RELEASE.2024-09-13T20-26-02Z.fips \
server /data --console-address ":9001"下一步,我們將部署 Iceberg Rest 目錄。這是一個表格貢獻的圖像,帶有一個瘦伺服器,用於公開由現有目錄實作支援的 Iceberg Rest 目錄伺服器端實作:
docker run --name iceberg-rest --net data-network -p 8181:8181 \
--env-file ./env.list \
tabulario/iceberg-rest:1.6.0在這裡,我們以檔案形式提供環境變量,其中包含 Iceberg REST 目錄與 Minio 配合使用的所有必要配置:
CATALOG_WAREHOUSE=s3://warehouse/
CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
CATALOG_S3_ENDPOINT=http://minio:9000
CATALOG_S3_PATH-STYLE-ACCESS=true
AWS_ACCESS_KEY_ID=minioadmin
AWS_SECRET_ACCESS_KEY=minioadmin
AWS_REGION=us-east-1現在,我們將部署 Trino 來處理 Iceberg REST 目錄。我們可以透過提供屬性檔案作為磁碟區掛載來配置 Trino 以使用我們先前部署的 REST 目錄和 Minio:
docker run --name trino --net data-network -p 8080:8080 \
--volume .\catalog:/etc/trino/catalog \
--env-file ./env.list \
trinodb/trino:449屬性檔包含 REST 目錄和 Minio 的詳細資訊:
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://iceberg-rest:8181/
iceberg.rest-catalog.warehouse=s3://warehouse/
iceberg.file-format=PARQUET
hive.s3.endpoint=http://minio:9000
hive.s3.path-style-access=true和之前一樣,我們也將環境變數作為包含 Minio 存取憑證的檔案提供:
AWS_ACCESS_KEY_ID=minioadmin
AWS_SECRET_ACCESS_KEY=minioadmin
AWS_REGION=us-east-1屬性hive.s3.path-style-access對於 Minio 是必要的,如果我們使用 AWS S3,則不需要。
5.2.數據操作
我們可以使用 Trino 對 REST 目錄執行不同的操作。 Trino 附帶了一個內建的 CLI ,讓我們更容易做到這一點。讓我們先從 Docker 容器內存取 CLI:
docker exec -it trino trino這應該為我們提供類似 shell 的提示來提交 SQL 查詢。正如我們之前所看到的,Iceberg 的客戶端需要先存取目錄。讓我們看看是否有可用的預設目錄:
trino> SHOW catalogs;
Catalog
---------
iceberg
system
(2 rows)我們將使用iceberg 。讓我們先在 Trino 中建立一個模式(它轉換為 Iceberg 中的命名空間):
trino> CREATE SCHEMA iceberg.demo;
CREATE SCHEMA現在,我們可以在這個模式中建立一個表格:
trino> CREATE TABLE iceberg.demo.customer (
-> id INT,
-> first_name VARCHAR,
-> last_name VARCHAR,
-> age INT);
CREATE TABLE讓我們插入幾行:
trino> INSERT INTO iceberg.demo.customer (id, first_name, last_name, age) VALUES
-> (1, 'John', 'Doe', 24),
-> (2, 'Jane', 'Brown', 28),
-> (3, 'Alice', 'Johnson', 32),
-> (4, 'Bob', 'Williams', 26),
-> (5, 'Charlie', 'Smith', 35);
INSERT: 5 rows我們可以查詢表格來取得插入的資料:
trino> SELECT * FROM iceberg.demo.people;
id | first_name | last_name | age
----+------------+-----------+-----
1 | John | Doe | 24
2 | Jane | Brown | 28
3 | Alice | Johnson | 32
4 | Bob | Williams | 26
5 | Charlie | Smith | 35
(5 rows)正如我們所看到的,我們可以使用熟悉的 SQL 語法來處理大量資料的高度可擴展和開放的表格式。
5.3.瀏覽文件
讓我們看看我們的儲存空間中產生了什麼類型的檔案。
Minio 提供了一個控制台,我們可以透過http://localhost:9001存取。我們在warehouse/demo下找到兩個目錄:
-
data和 -
metadata
我們首先查看元資料目錄:
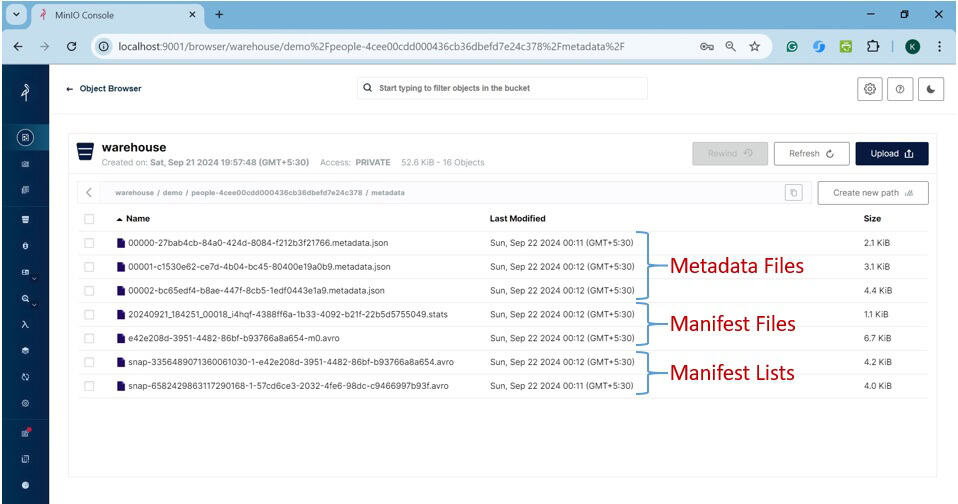
它包含元資料檔案 ( *.metadata.json )、清單清單 ( snap-*.avro ) 和清單檔案 ( *.avro, *.stats )。 .stats檔案包含有關用於提高查詢效能的表格資料的資訊。
現在,讓我們看看data目錄中有什麼:
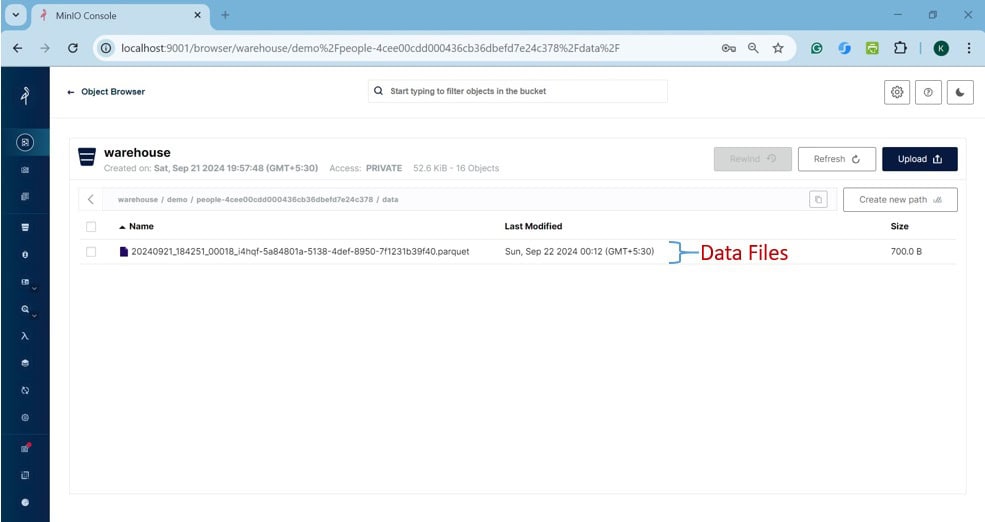
它有一個 Parquet 格式的資料文件,其中包含我們透過查詢建立的實際資料。
六、結論
Apache Iceberg 已成為當今實施資料湖站的熱門選擇。它提供快照、隱藏分區和就地表演化等功能。
它與 REST 目錄規範一起,迅速成為開放式表格式的事實上的標準。