Java Volatile變量和線程安全
- java
1. 概述
儘管volatile關鍵字通常可確保線程安全,但情況並非總是如此。
在本教程中,我們將研究共享volatile變量可能導致競爭條件的情況。
2. 什麼是volatile變量?
與其他變量不同, volatile變量在主存儲器中寫入和讀取。 CPU 不會緩存volatile變量的值。
讓我們看看如何聲明一個volatile變量:
static volatile int count = 0;3. volatile變量的屬性
在本節中,我們將了解volatile變量的一些重要特性。
3.1.可見性保證
假設我們有兩個線程,運行在不同的 CPU 上,訪問一個共享的非易失volatile變量。讓我們進一步假設第一個線程正在寫入一個變量,而第二個線程正在讀取同一個變量。
出於性能原因,每個線程都將變量的值從主內存複製到其各自的 CPU 緩存中。
volatile變量的情況下,JVM 不保證值何時會從緩存寫回主內存。
如果第一個線程的更新值沒有立即刷新回主內存,則第二個線程可能最終讀取舊值。
下圖描述了上述場景:
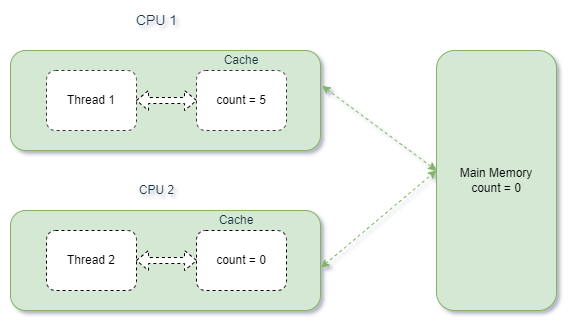
在這裡,第一個線程已將變量count的值更新為 5。但是,將更新的值刷新回主內存並不會立即發生。因此,第二個線程讀取較舊的值。這可能會在多線程環境中導致錯誤的結果。
另一方面,如果我們將count聲明為volatile ,則每個線程都會在主內存中看到其最新更新的值,不會有任何延遲。
volatile關鍵字的可見性保證。它有助於避免上述數據不一致問題。
3.2.發生前保證
JVM 和 CPU 有時會重新排序獨立指令並並行執行它們以提高性能。
例如,讓我們看兩條獨立且可以同時運行的指令:
a = b + c;
d = d + 1;但是,有些指令無法並行執行,因為後一條指令取決於前一條指令的結果:
a = b + c;
d = a + e;此外,還可以對獨立指令進行重新排序。這可能會導致多線程應用程序中的錯誤行為。
假設我們有兩個線程訪問兩個不同的變量:
int num = 10;
boolean flag = false;此外,我們假設第一個線程增加num的值,然後將flag設置為true ,而第二個線程等待直到flag設置為true 。並且,一旦flag的值設置為true ,第二個線程就會讀取num.
因此,第一個線程應按以下順序執行指令:
num = num + 10;
flag = true;但是,讓我們假設 CPU 將指令重新排序為:
flag = true;
num = num + 10;在這種情況下,只要將標誌設置為true ,第二個線程就會開始執行。並且因為變量num尚未更新,第二個線程將讀取num的舊值,即 10。這會導致不正確的結果。
但是,如果我們將flag聲明為volatile ,則不會發生上述指令重新排序。
在變量上應用volatile關鍵字通過提供發生在先保證來防止指令重新排序。
這確保了在寫入volatile變量之前的所有指令都不會被重新排序以發生在它之後。同樣,讀取volatile變量之後的指令不能重新排序在它之前發生。
4. volatile關鍵字何時提供線程安全?
volatile關鍵字在兩種多線程場景中很有用:
- 當只有一個線程寫入
volatile變量而其他線程讀取其值時。因此,讀取線程會看到變量的最新值。 - 當多個線程寫入共享變量時,操作是原子的。這意味著寫入的新值不依賴於先前的值。
5. volatile不提供線程安全?
volatile關鍵字是一種輕量級的同步機制。
與synchronized方法或塊不同,當一個線程在臨界區工作時,它不會讓其他線程等待。因此,當對共享變量執行非原子操作或複合操作時volatile關鍵字不提供線程安全性。
諸如遞增和遞減之類的操作是複合操作。這些操作在內部涉及三個步驟:讀取變量的值,更新它,然後將更新的值寫回內存。
讀取值和將新值寫回內存之間的短暫時間間隔可能會產生競爭條件。在該時間間隔內,處理同一變量的其他線程可能會讀取並操作較舊的值。
此外,如果多個線程對同一個共享變量執行非原子操作,它們可能會覆蓋彼此的結果。
因此,在線程需要首先讀取共享變量的值以找出下一個值的情況下,將變量聲明為volatile將不起作用。
6. 例子
現在,我們將在示例的幫助下嘗試理解將變量聲明為volatile
為此,我們將聲明一個名為count volatile變量並將其初始化為零。我們還將定義一個方法來增加這個變量:
static volatile int count = 0;
void increment() {
count++;
}接下來,我們將創建兩個線程t1和t2.這些線程調用了上面的增量操作一千次:
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for(int index=0; index<1000; index++) {
increment();
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for(int index=0; index<1000; index++) {
increment();
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();從上面的程序中,我們可能期望count變量的最終值是2000。但是,每次執行該程序,結果都會有所不同。有時,它會打印“正確”的值 (2000),有時則不會。
讓我們看一下運行示例程序時得到的兩個不同的輸出:
value of counter variable: 2000上述不可預測的行為是因為兩個線程都在對共享count變量執行增量操作。如前所述,增量操作不是原子的。它執行三個操作——讀取、更新,然後將變量的新值寫入主內存。 t1和t2同時運行時,這些操作很可能會發生交錯。
讓我們假設t1和t2同時運行,並且t1 count變量執行增量操作。但是,在將更新的值寫回主內存之前,線程t2 count變量的值。在這種情況下, t2將讀取一個較舊的值並對其執行增量操作。**這可能會導致更新到主內存count**變量的值不正確。因此,結果將與預期的 2000 年不同。
7. 結論
在本文中,我們看到將共享變量聲明為volatile並不總是線程安全的。
我們了解到,為了提供線程安全並避免非原子操作的競爭條件,使用synchronized方法或塊或原子變量都是可行的解決方案。