Gatling 測試監控
1. 概述
Gatling 是一個成熟且高效的效能測試工具,我們可以使用它來對我們的 REST 應用程式產生負載。但我們從 Gatling 中可以直接看到的唯一結果是斷言是否得到滿足以及我們的伺服器在壓力測試期間是否沒有崩潰。
我們希望獲得的資訊遠不止這些。在效能測試中,我們希望有 JVM 監控,以便我們知道它是否**以最佳方式運作和執行。**
在本文中,我們將設定一些工具來幫助我們在執行 Gatling 模擬時監控應用程式。設定將在容器層級進行,我們將在演示期間使用 Docker Compose 進行本地執行。我們全面測試和監控效能方面所需的工具是:
- 公開指標的 REST 應用程式。 Spring Boot Actuator 可用於取得本教學所需的指標,無需額外努力
- Prometheus 將成為從 REST 應用程式收集指標並將其儲存為時間序列資料的工具
- InfluxDB 是一個時間序列資料庫,用於從 Gatling 收集指標
- Grafana 可以將結果以漂亮的圖形形式可視化,讓我們可以輕鬆地與前面提到的資料來源集成,我們還可以保存 Grafana 儀表板並重複使用它們
2. 設定監控工具
為了示範如何實現良好的監控,我們將使用容器和 Docker Compose 來啟動和協調所有工具。對於每個工具,我們都需要一個包含建立容器說明的Dockerfile 。然後,我們將透過Docker Compose啟動所有服務。這將使服務之間的執行和通訊變得更加容易。
2.1. REST API
讓我們從用於執行效能測試的 REST API 開始。我們將使用一個具有兩個端點的簡單 Spring Boot MVC 應用程式。因為我們的重點是監控效能測試,所以兩個端點都是虛擬的。只需返回一個簡單的 OK 響應就足夠了。
我們之所以要設定兩個端點,是因為一個端點會立即回覆 200,而第二個端點會有一些隨機延遲,大概一到兩秒,然後才回傳成功回應:
@RestController
public class PerformanceTestsController {
@GetMapping("/api/fast-response")
public ResponseEntity<String> getFastResponse() {
return ResponseEntity.ok("was that fast enough?");
}
@GetMapping("/api/slow-response")
public ResponseEntity<String> getSlowResponse() throws InterruptedException {
int min = 1000;
int max = 2000;
TimeUnit.MILLISECONDS.sleep(ThreadLocalRandom.current()
.nextInt(min, max));
return ResponseEntity.ok("this took a while");
}
}然後,我們需要透過建立Dockerfile來容器化該服務:
FROM openjdk:17-jdk-slim
COPY target/gatling-java.jar app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
EXPOSE 8080首先,我們選擇所需的基礎鏡像,在本例中是 Java 17 鏡像。然後,我們複製啟動伺服器所需的工件。我們所需要的只是我們創建的 Spring Boot 應用程式 JAR 文件,然後將其設定為容器的ENTRYPOINT 。最後,我們提到需要導出作為容器接入點的連接埠(8080)。
2.2.普羅米修斯
創建 Prometheus 容器我們需要做的就是找到我們想要使用的 Prometheus 版本的基礎鏡像。然後,我們配置想要抓取指標的目標。
讓我們在configuration.yml檔案中定義目標的配置:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'grafana'
scrape_interval: 5s
metrics_path: /metrics
static_configs:
- targets: ['grafana:3000']
- job_name: 'service_metrics'
scrape_interval: 5s
metrics_path: /private/metrics
static_configs:
- targets: ['service:8080']首先,我們將抓取和評估間隔設定為 15 秒,以獲取更頻繁、更準確的資料。請注意,在現實環境中,該頻率可能會引起不必要的噪音。預設值通常為30秒。
在scrape_configs中,我們新增了三個作業:
-
prometheus將從localhost的 Prometheus 實例中抓取數據,以監控 Prometheus 在效能測試執行期間是否健康。我們之所以包括這一點,是因為不健康的監測工具可能會導致不準確的結果。 -
grafana指向grafana服務。我們需要做的就是設定主機和路徑。主機是grafana:3000,只有透過 Docker Compose 運行服務時才會運作。 Grafana 服務的預設路徑為/metrics。 -
service_metrics將從我們的 Spring Boot 應用程式中讀取指標。與grafana類似,我們將主機設定為service:8080以用於 Docker Compose 執行,並透過 Spring Boot Actuator 設定定義路徑。
一旦我們有了configuration.yml文件,我們就需要定義Dockerfile :
FROM prom/prometheus:v2.48.1
COPY config/prometheus-docker.yml /etc/prometheus/prometheus.yml
EXPOSE 9090:9090我們首先選擇我們想要使用的 Prometheus 影像版本。然後,我們複製並覆蓋 Prometheus 期望在/etc/prometheus/prometheus.yml中找到的配置。最後,我們提到需要導出作為容器接入點的連接埠(9090)。
2.3.加特林
為了對我們創建的兩個端點執行效能測試,我們需要建立一個 Gatling 模擬,以產生我們想要的負載和持續時間,以測試我們的服務。為了更好地演示,我們將進行兩次 Gatling 模擬,一次用於第一個端點,一次用於第二個端點:
public class SlowEndpointSimulation extends Simulation {
public SlowEndpointSimulation() {
ChainBuilder getSlowEndpointChainBuilder
= SimulationUtils.simpleGetRequest("request_slow_endpoint", "/api/slow-response", 200);
PopulationBuilder slowResponsesPopulationBuilder
= SimulationUtils.buildScenario("getSlowResponses", getSlowEndpointChainBuilder, 120, 30, 300);
setUp(slowResponsesPopulationBuilder)
.assertions(
details("request_slow_endpoint").successfulRequests().percent().gt(95.00),
details("request_slow_endpoint").responseTime().max().lte(10000)
);
}
}SlowEndpointSimulation針對/api/slow-response路徑設定一個名為request_slow_endpoint的模擬。尖峰負載為每秒 120 個請求,持續 300 秒,我們斷言 95% 的回應應該會成功,且回應時間應該少於 10 秒。
類似地,我們為第二個端點定義模擬:
public class FastEndpointSimulation extends Simulation {
public FastEndpointSimulation() {
ChainBuilder getFastEndpointChainBuilder
= SimulationUtils.simpleGetRequest("request_fast_endpoint", "/api/fast-response", 200);
PopulationBuilder fastResponsesPopulationBuilder
= SimulationUtils.buildScenario("getFastResponses", getFastEndpointChainBuilder, 200, 30, 180);
setUp(fastResponsesPopulationBuilder)
.assertions(
details("request_fast_endpoint").successfulRequests().percent().gt(95.00),
details("request_fast_endpoint").responseTime().max().lte(10000)
);
}
}FastEndpointSimulation類別的作用與SlowEndpointSimulation相同,但名稱不同,為request_fast_endpoint ,並且針對/api/fast-response路徑。我們將此交易設置為每秒 200 個,以更好地強調應用程序,持續 180 秒。
為了讓 Gatling 匯出可從 Grafana 監控和儲存的指標,我們需要配置 Gatling 以將它們公開給 Graphite。資料將指向 InfluxDB 實例,該實例將儲存資料。最後,Grafana 將從 InfluxDB(作為其資料來源)讀取 Gatling 公開的指標,我們將能夠創建漂亮的圖表來對其進行視覺化。
為了能夠將指標公開到 Graphite,我們需要在gatling.conf檔案中加入配置:
data {
writers = [console, file, graphite]
console {
}
file {
}
leak {
}
graphite {
light = false
host = "localhost"
port = 2003
protocol = "tcp"
rootPathPrefix = "gatling"
bufferSize = 8192
writePeriod = 1
}
}我們添加了額外的graphite寫入器並設定了所需的配置。 host是localhost ,因為 InfluxDB 將在 Docker Compose 中運行,並且可以在我們的本地主機上存取。該port應該與InfluxDb公開的連接埠相匹配, 2003 。最後,我們將單字gatling設定為rootPathPrefix ,這將是我們公開的指標的前綴。其餘屬性只是為了更好的調整。
Gatling 的執行將不會成為 Docker Compose 的一部分。透過 Docker Compose 啟動所有服務後,我們可以使用控制台運行任何我們想要的 Gatling 場景,模擬服務的真實外部用戶端。
2.4.流入資料庫
設定 InfluxDB 並不像其他工具那麼簡單。首先,我們需要一個目標版本的基礎鏡像,然後是一個configuration.conf文件,以及一個ENTRYPOINT文件,其中包含一些額外的容器配置,用於儲存 Gatling 匯出的資料。
我們需要的設定是關於Graphite的。我們需要在influxdb.conf檔案中啟用 Graphite 端點,以便 Gatling 可以發布其執行資料:
[[graphite]]
enabled = true
database = "graphite"
retention-policy = ""
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
batch-size = 5000
batch-pending = 10
batch-timeout = "1s"
separator = "."
udp-read-buffer = 0首先,我們設定enabled = true並加入一些關於資料庫的屬性,例如retention policy, consistency level等,以及一些連線屬性,例如protocol 、 bind-address等。這裡的重要屬性是我們設定為bind-address的端口,因此我們可以在 Graphite 配置中的 Gatling 中使用它。
下一步是建立實例化 influx 資料庫並建立資料庫的entrypoint.sh文件,使用我們建立的設定檔:
#!/usr/bin/env sh
if [ ! -f "/var/lib/influxdb/.init" ]; then
exec influxd -config /etc/influxdb/influxdb.conf $@ &
until wget -q "http://localhost:8086/ping" 2> /dev/null; do
sleep 1
done
influx -host=localhost -port=8086 -execute="CREATE USER ${INFLUX_USER} WITH PASSWORD '${INFLUX_PASSWORD}' WITH ALL PRIVILEGES"
influx -host=localhost -port=8086 -execute="CREATE DATABASE ${INFLUX_DB}"
touch "/var/lib/influxdb/.init"
kill -s TERM %1
fi
exec influxd $@首先,我們執行influxd並指向我們建立的設定檔。然後,我們在until循環中等待,直到服務可用。最後,我們啟動資料庫。
建立所有先決條件後, Dockerfile的建立應該很簡單:
FROM influxdb:1.3.1-alpine
WORKDIR /app
COPY entrypoint.sh ./
RUN chmod u+x entrypoint.sh
COPY influxdb.conf /etc/influxdb/influxdb.conf
ENTRYPOINT ["/app/entrypoint.sh"]首先,我們使用我們選擇的版本的基礎映像,然後將檔案複製到容器並授予必要的存取權限,最後,我們將ENTRYPOINT設定為我們建立的entrypoint.sh檔案。
2.5.格拉法納
在容器中啟動 Grafana 服務很簡單。我們只需使用 Grafana 提供的其中一個圖像即可。在我們的例子中,我們還將在圖像中包含一些設定檔和儀表板。這可以在我們啟動服務後手動完成,但為了獲得更好的體驗並將配置和儀表板儲存在 VCS 中,以便保存歷史記錄和備份,我們將預先建立檔案。
首先,我們在yml檔案中設定資料來源:
datasources:
- name: Prometheus-docker
type: prometheus
isDefault: false
access: proxy
url: http://prometheus:9090
basicAuth: false
jsonData:
graphiteVersion: "1.1"
tlsAuth: false
tlsAuthWithCACert: false
version: 1
editable: true
- name: InfluxDB
type: influxdb
uid: P951FEA4DE68E13C5
isDefault: false
access: proxy
url: http://influxdb:8086
basicAuth: false
jsonData:
dbName: "graphite"
version: 1
editable: true第一個來源是Prometheus,第二個是InfluxDB。重要的配置是url ,以確保我們正確指向 Docker Compose 中運行的兩個服務。
然後,我們建立一個yml檔案來定義 Grafana 可以從中檢索我們儲存的儀表板的路徑:
providers:
- name: 'dashboards'
folder: ''
type: file
disableDeletion: false
allowUiUpdates: true
editable: true
options:
path: /etc/grafana/provisioning/dashboards
foldersFromFilesStructure: true這裡我們需要正確設定路徑。然後,我們將其包含在Dockerfile中以儲存我們的儀表板的 JSON 檔案:
FROM grafana/grafana:10.2.2
COPY provisioning/ /etc/grafana/provisioning/
COPY dashboards/ /etc/grafana/provisioning/dashboards
EXPOSE 3000:3000在Dockerfile中,我們設定了想要使用的 Grafana 版本的基礎映像。然後,我們將設定檔從provisioning複製到/etc/grafana/provisioning/ ,其中 Grafana 將查找配置和dashboards板資料夾中的/etc/grafana/provisioning/dashboards dashboards 。最後,我們提到了我們想要為服務公開的連接埠3000 。
請注意,為了演示,我們在dashboards資料夾中建立了兩個儀表板檔案 - application-metrics.json和gatling-metrics.json ,但它們太長,無法包含在本文中。
2.6. Docker 組成
建立完所有服務後,我們將所有內容整合到 Docker Compose 中:
services:
influxdb:
build: influxDb
ports:
- '8086:8086'
- '2003:2003'
environment:
- INFLUX_USER=admin
- INFLUX_PASSWORD=admin
- INFLUX_DB=influx
prometheus:
build: prometheus
depends_on:
- service
ports:
- "9090:9090"
grafana:
build: grafana
ports:
- "3000:3000"
service:
build: .
ports:
- "8080:8080"Docker Compose 將啟動四項服務 - influxdb 、 prometheus 、 grafana和service 。請注意,這裡使用的名稱將作為這些服務內部通訊的主機。
3. 監控 Gatling 測試
現在我們已經設定好了工具,我們可以透過 Docker Compose 啟動所有監控服務和 REST API 伺服器。然後,我們可以運行在 Gatling 中創建的效能測試並存取 Grafana 來監控效能。
3.1.執行測試
第一步是透過從我們的終端運行docker-compose up –build透過 Docker Compose 啟動所有服務。當它們全部啟動並正常運作時,我們可以使用終端和 Maven 執行 Gatling 模擬。
例如,對於第二次模擬,我們需要執行mvn gatling:test -Dgatling.simulationClass=org.baeldung.FastEndpointSimulation :
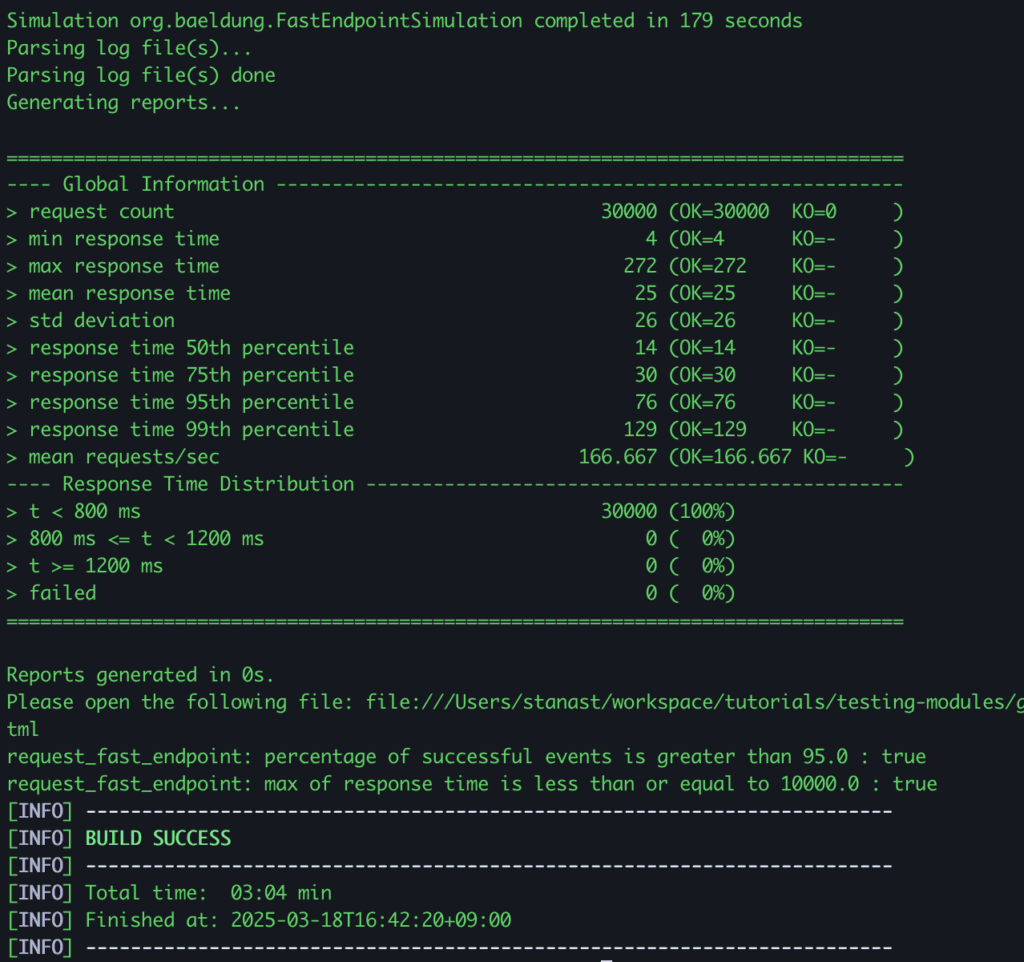
正如我們在結果中看到的,我們的“模擬在 179 秒內完成”並且所有斷言都得到滿足。
3.2.使用 Grafana 儀表板進行監控
現在,讓我們訪問Grafana來檢查我們收集的監控數據。我們可以從瀏覽器存取http://localhost:3000/上的 Grafana,並在使用者名稱和密碼欄位中使用「admin」登入。應該有兩個現有的儀表板,每個儀表板對應我們透過Dockerfile包含的兩個儀表板 JSON 檔案。
第一個儀表板為我們提供了應用程式指標的視覺化:
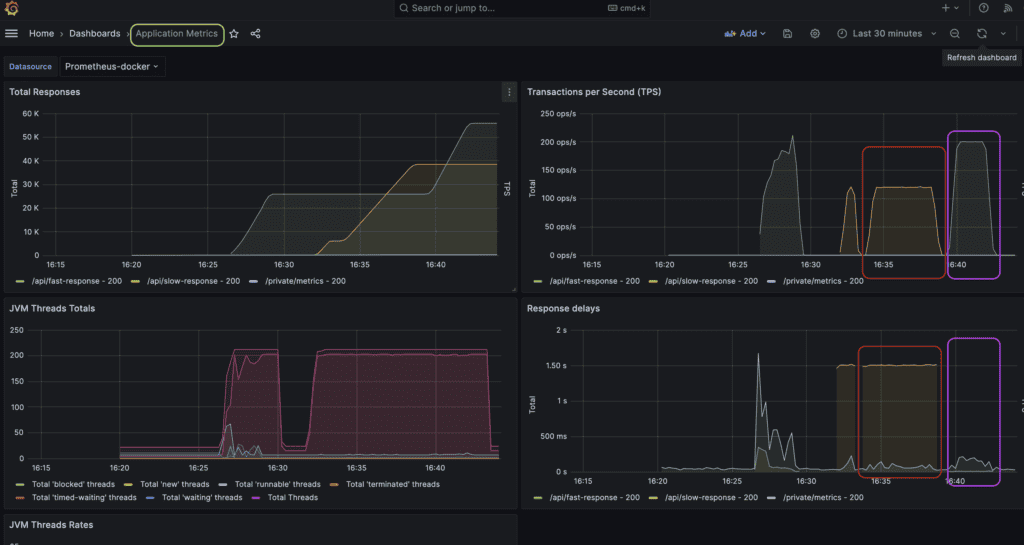
在每秒事務數 (TPS) 和回應延遲視圖中,我們可以觀察到 Gatling 產生了預期的負載。紅色圓圈標記的指標針對的是慢速端點效能測試。執行耗時300s,TPS為120,反應延遲約1.5s。
紫色突出顯示的指標用於快速端點效能測試。此模擬持續了 180 秒,TPS 為 200,回應延遲要小得多,因為該端點立即回復成功回應。
第二個儀表板是關於 Gatling 指標的,它顯示了客戶端對回應代碼、延遲等的看法:
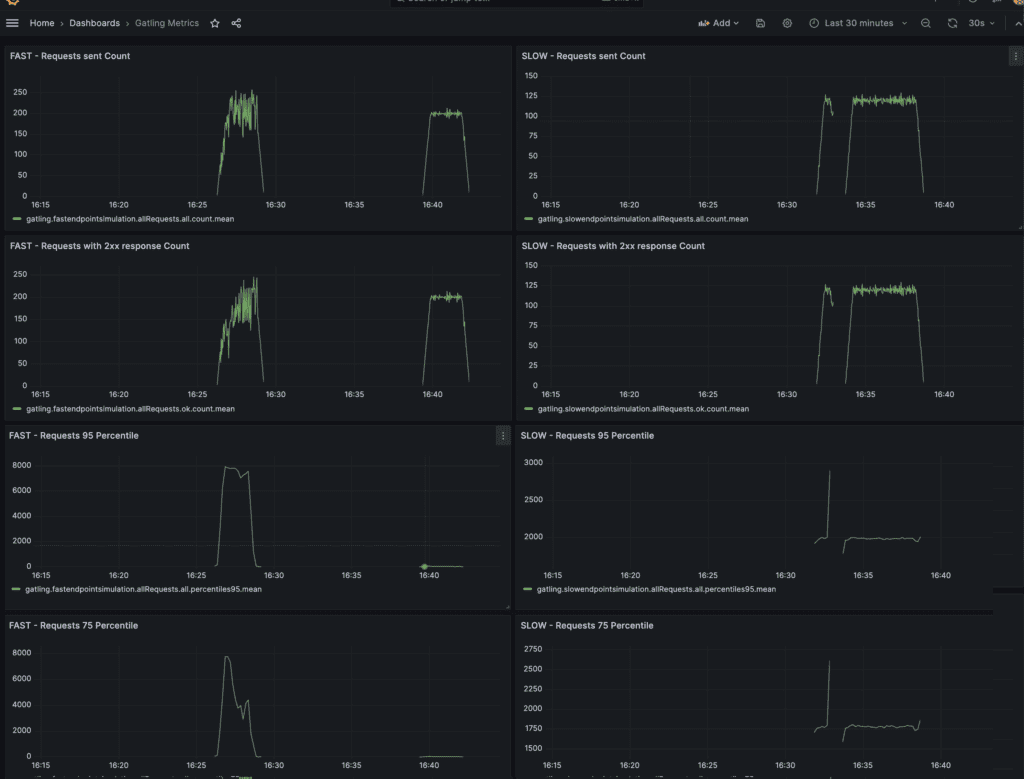
在這個儀表板中,我們可以在左側看到從 Gatling 收集的用於快速端點測試模擬的指標,在右側看到用於慢速端點測試模擬的指標。我們可以驗證產生的流量是否符合預期,並且回應狀態和延遲與我們在應用程式指標儀表板上看到的內容準確相對應。
3.3.解讀結果
現在一切就緒,讓我們調整 JVM。透過讀取指標,我們可以識別可能的錯誤,並嘗試以不同的方式調整 JVM 以提高效能。
現有儀表板可以查看 JVM 執行緒指標。例如,我們可以看到每個端點使用了多少個執行緒。然後,我們可以進行觀察,例如測試特定端點時的執行緒數是否高於預期。如果是這樣,這可能意味著我們在這個特定端點的實作中過度使用了執行緒。
監控 JVM 的另一個重要面向是垃圾收集指標。我們應該始終包含有關 GC 頻率、持續時間和其他因素的儀表板。然後,我們可以嘗試不同的垃圾收集和配置,重新執行我們的效能測試,並為我們的 API 找到最佳解決方案。
4. 結論
在本文中,我們研究如何在使用 Gatling 執行效能測試時設定適當的監控。我們設定了監控 REST API 和 Gatling 所需的工具,並示範了一些測試執行。最後,我們使用 Grafana 儀表板讀取結果,並提到了執行效能測試時需要關注的一些指標,例如與 JVM 執行緒和垃圾收集相關的指標。
與往常一樣,範例中使用的所有原始程式碼都可以在 GitHub 上找到。