尋找數組中第一個重複元素的索引
1. 概述
尋找數組中第一個重複元素的索引是一個常見的編碼問題,可以透過多種方式解決。雖然蠻力方法很簡單,但效率可能很低,尤其是對於大型資料集。
在本教程中,我們將探索解決此問題的不同方法,從基本的暴力解決方案到使用HashSet和數組索引等資料結構的更優化技術。
2. 問題陳述
給定一個整數數組,我們想要找出數組中第一個重複元素的索引。
輸入: arr = [2, 1, 3, 5, 3, 2]
輸出: 4
解釋:第一個重複的元素是3 ,第二次出現的位置是索引4 。所以正確答案是4 。
輸入: arr = [1, 2, 3, 4, 5]
輸出: -1
解釋:由於沒有元素重複,所以正確答案是-1 。
3. 蠻力方法
在這種方法中,我們檢查數組的每個元素並將其與所有後續元素進行比較以找到第一個重複項。
我們先看一下實現,然後逐步理解:
int firstDuplicateBruteForce(int[] arr) {
int minIndex = arr.length;
for (int i = 0; i < arr.length - 1; i++) {
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] == arr[j]) {
minIndex = Math.min(minIndex, j);
break;
}
}
}
return minIndex == arr.length ? -1 : minIndex;
}讓我們回顧一下這段程式碼:
- 我們循環遍歷每個元素
i,並且對於每個元素,我們在後面的索引j處查找其重複項。 - 當我們找到重複項時,我們將
j(第二次出現的索引)與minIndex進行比較,後者追蹤任何重複項最早的第二次出現。 - 中斷確保我們只追蹤每個元素重複出現的第一秒。
- 最後,如果
minIndex沒有更新,則表示沒有重複項,因此我們傳回-1。
現在,我們來討論時間和空間複雜度。我們使用兩個巢狀循環,每個循環都遍歷數組,導致時間複雜度為二次方。所以,時間複雜度是O(n^2) 。由於我們使用的額外空間與輸入的大小無關,因此空間複雜度為O(1) 。
4.使用HashSet
我們可以使用HashSet來儲存到目前為止我們看到的元素。當我們迭代數組時,我們檢查是否已經看到一個元素。如果是這樣,我們將其索引作為第一個重複項傳回。
我們先看一下實現,然後逐步理解:
int firstDuplicateHashSet(int[] arr) {
HashSet<Integer> firstDuplicateSet = new HashSet<>();
for (int i = 0; i < arr.length; i++) {
if (firstDuplicateSet.contains(arr[i])) {
return i;
}
firstDuplicateSet.add(arr[i]);
}
return -1;
}讓我們回顧一下這段程式碼:
- 創建一個空的
HashSet。 - 循環遍歷數組。
- 對於每個元素,檢查它是否存在於
HashSet.- 如果是,則傳回索引(第一個重複項)。
- 如果沒有,則將該元素新增至集合。
- 如果沒有找到重複項,則傳回
-1。
現在我們將考慮我們在開始時提到的範例並進行一次演練:
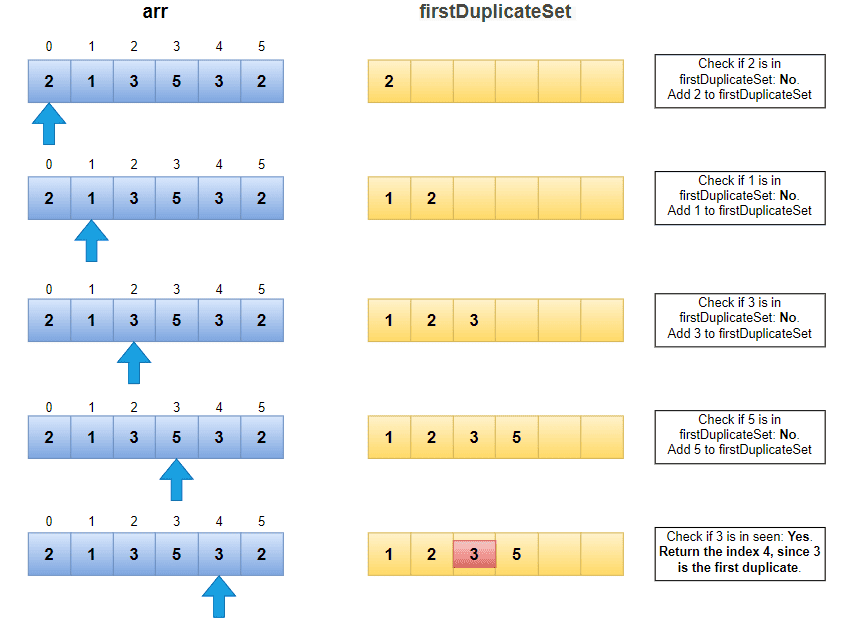
如果我們考慮時間和空間複雜度,我們會迭代一次數組,在HashSet中檢查/插入元素平均為O(1) ,因此時間複雜度為O(n) 。在最壞的情況下,我們可能需要儲存HashSet中的所有元素,因此空間複雜度為O(n) 。
5. 使用陣列索引
如果元素為正且在特定範圍內,即大小為n的數組在1和n之間,我們可以透過修改數組本身來避免使用額外的空間。這種方法的工作原理是假設所有元素都是正數並且在[1, n]範圍內。
我們先看一下實現,然後逐步理解:
int firstDuplicateArrayIndexing(int[] arr) {
for (int i = 0; i < arr.length; i++) {
int val = Math.abs(arr[i]) - 1;
if (arr[val] < 0) {
return i;
}
arr[val] = -arr[val];
}
return -1;
}讓我們回顧一下這段程式碼:
- 迭代數組。
- 對於每個元素,將值視為索引並將相應元素標記為負數。
- 如果我們在計算的索引處遇到負值,則表示已經遇到該元素,並且我們會傳回目前索引作為第一個重複項。
- 如果沒有找到重複項,則傳回
-1。
現在我們將考慮我們在開始時提到的範例並進行一次演練:
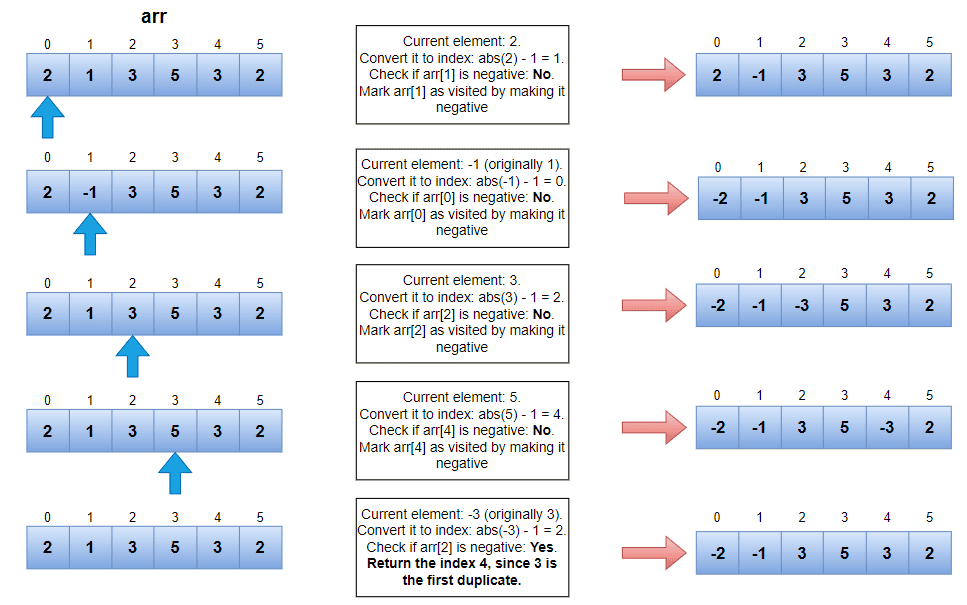
現在,我們來討論時間和空間複雜度。由於我們遍歷數組一次,時間複雜度將為O(n),並且由於我們沒有使用額外的空間,因此空間複雜度將為O(1) 。
六、結論
在本文中,我們看到可以使用不同的策略來識別數組中的第一個重複項,每種策略都有其時間和空間複雜性權衡。
蠻力方法雖然簡單,但由於其O(n^2)時間複雜度,對於較大的資料集並不理想。最佳化方法可顯著提高效能,例如使用HashSet或修改陣列。
選擇正確的解決方案取決於問題的約束,例如是否允許額外的空間或是否可以修改陣列。了解這些技術為我們提供了有效解決類似問題的多功能工具。
與往常一樣,本文中提供的程式碼可以在 GitHub 上取得。