使用 Langchain4j 和 MongoDB Atlas 在 Java 中建立 AI 聊天機器人
1.概述
聊天機器人系統透過提供快速、智慧的回應來增強使用者體驗,使互動更加有效率。
在本教程中,我們將介紹使用 Langchain4j 和 MongoDB Atlas 建立聊天機器人的過程。
LangChain4j 是一個受LangChain啟發的 Java 程式庫,旨在幫助使用 LLM 建立 AI 驅動的應用程式。我們用它來開發聊天機器人、摘要引擎或智慧搜尋系統等應用程式。
我們將使用MongoDB Atlas Vector Search**使我們的聊天機器人能夠根據含義(而不僅僅是關鍵字)檢索相關資訊**。傳統的基於關鍵字的搜尋方法依賴於精確的詞語匹配,當使用者以不同的方式提出問題或使用同義詞時,往往會導致不相關的結果。
透過使用向量儲存和向量搜索,我們的應用程式將使用者查詢的含義與儲存的內容映射到高維向量空間中,從而進行比較。這使得聊天機器人能夠以更高的上下文準確性理解和回答複雜的自然語言問題,即使來源內容中沒有出現確切的單字。因此,我們獲得了更多情境感知的結果。
2. AI聊天機器人應用程式架構
讓我們來看看我們的應用程式元件:
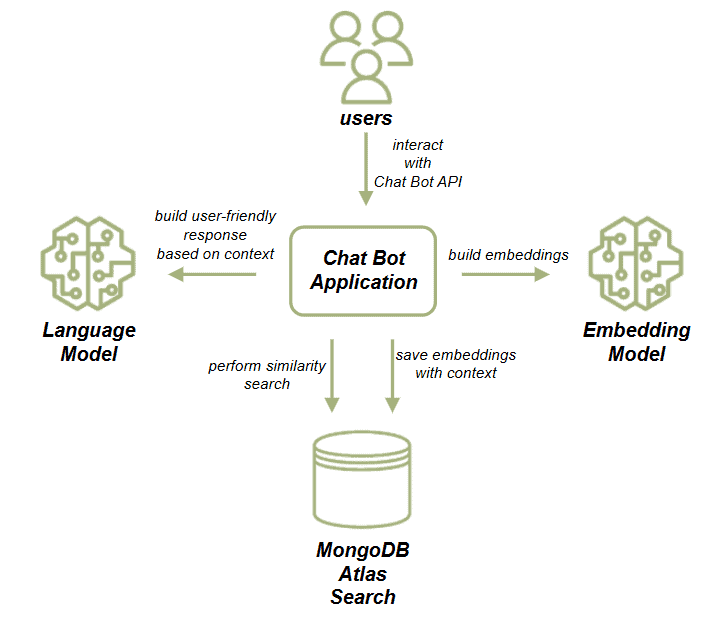
我們的應用程式使用 HTTP 端點與聊天機器人互動。它有兩個流程:文件載入流程和聊天機器人流程。
對於文件載入流程,我們將採用文章資料集。然後,我們將使用嵌入模型產生向量嵌入。最後,我們將嵌入與資料一起保存在 MongoDB 中。這些嵌入代表了文章的語義內容,從而實現了高效的相似性搜尋。
對於聊天機器人流程,我們將根據使用者輸入在 MongoDB 實例中執行相似性搜索,以檢索最相關的文件。在此之後,我們將使用檢索到的文章作為 LLM 提示的上下文,並根據 LLM 輸出產生聊天機器人的回應。
3.依賴項和配置
讓我們先加入spring-boot-starter-web依賴項,因為我們將建立 HTTP API:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.3.2</version>
</dependency>接下來,讓我們加入langchain4j-mongodb-atlas依賴項,它提供與 MongoDB 向量儲存和嵌入模型通訊的介面:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mongodb-atlas</artifactId>
<version>1.0.0-beta1</version>
</dependency>最後,我們將新增langchain4j依賴項。這為我們提供了與嵌入模型和 LLM 互動所需的介面:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta1</version>
</dependency>為了演示目的,我們將設定本地 MongoDB 叢集。接下來,我們將取得OpenAI API 金鑰。現在,我們可以在application.properties檔案中設定 MongoDB URL、資料庫名稱和 OpenAI API 金鑰:
app.mongodb.url=mongodb://chatbot:password@localhost:27017/admin
app.mongodb.db-name=chatbot_db
app.openai.apiKey=${OPENAI_API_KEY}現在,讓我們建立一個ChatBotConfiguration類別。在這裡,我們將定義 MongoDB 客戶端 bean 和與嵌入相關的 bean:
@Configuration
public class ChatBotConfiguration {
@Value("${app.mongodb.url}")
private String mongodbUrl;
@Value("${app.mongodb.db-name}")
private String databaseName;
@Value("${app.openai.apiKey}")
private String apiKey;
@Bean
public MongoClient mongoClient() {
return MongoClients.create(mongodbUrl);
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore(MongoClient mongoClient) {
String collectionName = "embeddings";
String indexName = "embedding";
Long maxResultRatio = 10L;
CreateCollectionOptions createCollectionOptions = new CreateCollectionOptions();
Bson filter = null;
IndexMapping indexMapping = IndexMapping.builder()
.dimension(TEXT_EMBEDDING_3_SMALL.dimension())
.metadataFieldNames(new HashSet<>())
.build();
Boolean createIndex = true;
return new MongoDbEmbeddingStore(
mongoClient,
databaseName,
collectionName,
indexName,
maxResultRatio,
createCollectionOptions,
filter,
indexMapping,
createIndex
);
}
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.modelName(TEXT_EMBEDDING_3_SMALL)
.build();
}
}我們使用 OpenAI text-embedding-3-small模型建構了EmbeddingModel 。當然,我們可以選擇其他符合我們需求的嵌入模型。然後,我們建立一個MongoDbEmbeddingStore bean。該商店由 MongoDB Atlas 集合支持,其中嵌入將被保存和索引,以實現快速語義檢索。接下來,我們將尺寸設定為預設的text-embedding-3-small值。使用**EmbeddingModel,我們需要確保創建的向量的維度與提到的模型相符。**
4. 將文檔資料載入到向量存儲
我們將使用 MongoDB 文章作為我們的 ChatBot 資料。為了演示目的,我們可以手動下載Hugging Face的文章資料集。接下來,我們將此資料集儲存為資源資料夾中的articles.json檔案。
我們希望在應用程式啟動期間提取這些文章,將它們轉換為向量嵌入並儲存在我們的 MongoDB Atlas 向量儲存中。
現在,讓我們將屬性新增到application.properties檔案中。我們將使用它來控制是否需要資料載入:
app.load-articles=true4.1.****文章庫
現在,讓我們建立ArticlesRepository ,負責讀取資料集、產生嵌入並儲存它們:
@Component
public class ArticlesRepository {
private static final Logger log = LoggerFactory.getLogger(ArticlesRepository.class);
private final EmbeddingStore<TextSegment> embeddingStore;
private final EmbeddingModel embeddingModel;
private final ObjectMapper objectMapper = new ObjectMapper();
@Autowired
public ArticlesRepository(@Value("${app.load-articles}") Boolean shouldLoadArticles,
EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) throws IOException {
this.embeddingStore = embeddingStore;
this.embeddingModel = embeddingModel;
if (shouldLoadArticles) {
loadArticles();
}
}
}這裡我們設定了 EmbeddingStore、嵌入模型和設定標誌。如果app.load-articles設定為true ,我們會在啟動時觸發文件提取。現在,讓我們實作*loadArticles()*方法:
private void loadArticles() throws IOException {
String resourcePath = "articles.json";
int maxTokensPerChunk = 8000;
int overlapTokens = 800;
List<TextSegment> documents = loadJsonDocuments(resourcePath, maxTokensPerChunk, overlapTokens);
log.info("Documents to store: " + documents.size());
for (TextSegment document : documents) {
Embedding embedding = embeddingModel.embed(document.text()).content();
embeddingStore.add(embedding, document);
}
log.info("Documents are uploaded");
}這裡我們使用loadJsonDocuments()方法來載入儲存在資源資料夾中的資料。我們建立一個TextSegment實例集合。對於每個 TextSegment,我們建立一個嵌入並將其儲存在向量儲存中。我們將使用**maxTokensPerChunk變數來指定向量儲存文件區塊中存在的最大標記數。該值應低於模型尺寸。此外,我們使用**overlapTokens**來指示文本段之間可能有多少個標記重疊。**這有助於我們保留片段之間的上下文。
4.2. loadJsonDocuments()**實現**
接下來,我們來介紹一下*loadJsonDocuments()*方法,該方法讀取原始 JSON 文章,將其解析為 LangChain4j Document對象,並準備嵌入:
private List<TextSegment> loadJsonDocuments(String resourcePath, int maxTokensPerChunk, int overlapTokens) throws IOException {
InputStream inputStream = ArticlesRepository.class.getClassLoader().getResourceAsStream(resourcePath);
if (inputStream == null) {
throw new FileNotFoundException("Resource not found: " + resourcePath);
}
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
int batchSize = 500;
List<Document> batch = new ArrayList<>();
List<TextSegment> textSegments = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
JsonNode jsonNode = objectMapper.readTree(line);
String title = jsonNode.path("title").asText(null);
String body = jsonNode.path("body").asText(null);
JsonNode metadataNode = jsonNode.path("metadata");
if (body != null) {
addDocumentToBatch(title, body, metadataNode, batch);
if (batch.size() >= batchSize) {
textSegments.addAll(splitIntoChunks(batch, maxTokensPerChunk, overlapTokens));
batch.clear();
}
}
}
if (!batch.isEmpty()) {
textSegments.addAll(splitIntoChunks(batch, maxTokensPerChunk, overlapTokens));
}
return textSegments;
}在這裡,我們解析 JSON 檔案並遍歷每個專案。然後,我們將文章標題、正文和元資料作為文件新增到批次中。一旦批次達到 500 個條目(或結束),我們將使用splitIntoChunks()對其進行處理,將內容分成可管理的文字段。 此方法傳回TextSegment物件的完整列表,可供嵌入和儲存。
讓我們實作*addDocumentToBatch()*方法:
private void addDocumentToBatch(String title, String body, JsonNode metadataNode, List<Document> batch) {
String text = (title != null ? title + "\n\n" + body : body);
Metadata metadata = new Metadata();
if (metadataNode != null && metadataNode.isObject()) {
Iterator<String> fieldNames = metadataNode.fieldNames();
while (fieldNames.hasNext()) {
String fieldName = fieldNames.next();
metadata.put(fieldName, metadataNode.path(fieldName).asText());
}
}
Document document = Document.from(text, metadata);
batch.add(document);
}文章的標題和正文連結成一個文字區塊。如果我們有元數據,我們會解析欄位並將它們添加到元數據物件中。組合的文字和元資料被包裝在一個 Document 物件中,我們將其新增到目前批次中。
4.3. splitIntoChunks()**實作及取得上傳結果**
一旦我們將文章組裝為包含內容和元資料的Document對象,下一步就是將它們拆分成更小的、可識別標記的區塊,這些區塊與我們的嵌入模型的限制相容。 最後,讓我們看看*splitIntoChunks()*是什麼樣子的:
private List<TextSegment> splitIntoChunks(List<Document> documents, int maxTokensPerChunk, int overlapTokens) {
OpenAiTokenizer tokenizer = new OpenAiTokenizer(OpenAiEmbeddingModelName.TEXT_EMBEDDING_3_SMALL);
DocumentSplitter splitter = DocumentSplitters.recursive(
maxTokensPerChunk,
overlapTokens,
tokenizer
);
List<TextSegment> allSegments = new ArrayList<>();
for (Document document : documents) {
List<TextSegment> segments = splitter.split(document);
allSegments.addAll(segments);
}
return allSegments;
}首先,我們初始化一個與 OpenAI 的 text-embedding-3-small 模型相容的標記器。然後,我們使用DocumentSplitter將文件分成區塊,同時保留相鄰區塊之間的重疊。每個文件都經過處理並拆分為多個TextSegment實例,然後返回以嵌入到我們的向量儲存(MongoDB)中。在引導過程中,我們應該看到以下日誌:
要儲存的文檔:328
儲存嵌入
此外,如果我們使用MongoDB Compass查看 MongoDB 中儲存的內容,我們將看到所有產生了嵌入的文件內容:
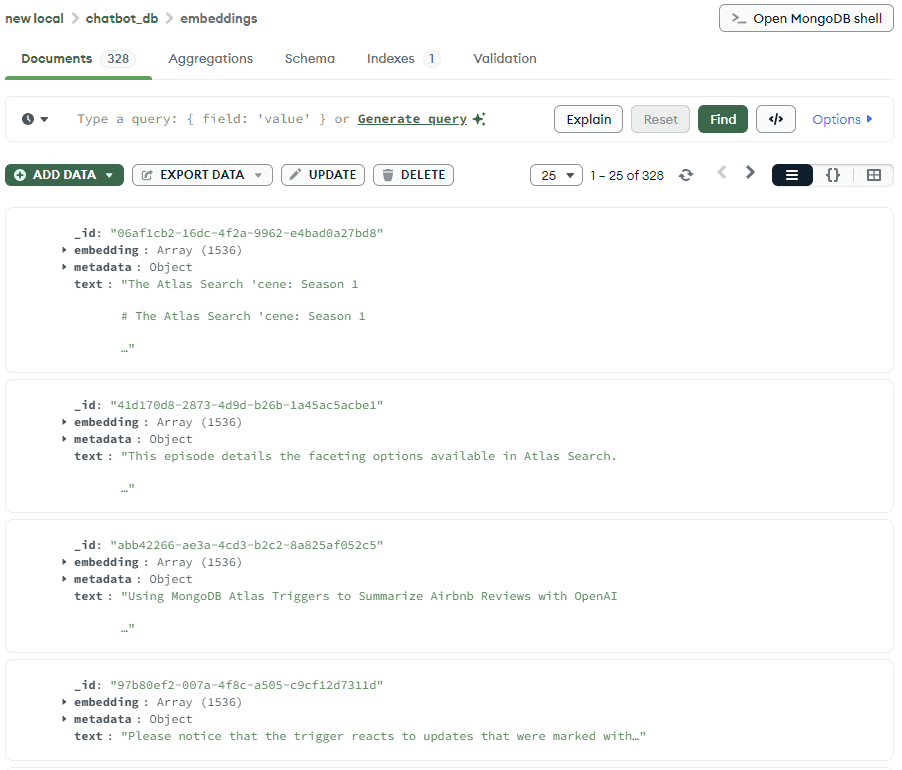
這個過程很重要,因為大多數嵌入模型都有標記限制。這意味著一次只能將一定量的資料嵌入向量中。分塊使我們能夠遵守這些限制,而重疊則幫助我們保持片段之間的連續性。這對於基於段落的內容尤其重要。
我們僅使用了整個資料集的一部分用於演示目的。上傳整個資料集可能需要一些時間並且需要更多積分。
5.聊天機器人API
現在,讓我們實作 Chatbot API 流程(我們的聊天機器人介面)。在這裡,我們將創建一些 bean,從向量儲存中檢索文件並與 LLM 通信,創建上下文感知回應。最後,我們將建立聊天機器人 API 並驗證其工作原理。
5.1.**基於文章的助手實現**
我們首先建立ContentRetriever bean,使用使用者的輸入在 MongoDB Atlas 中執行向量搜尋:
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(10)
.minScore(0.8)
.build();
}此檢索器使用嵌入模型對使用者的查詢進行編碼,並將其與儲存的文章嵌入進行比較。此外,我們指定了要傳回的最大結果項數和分數,這將控制回應與我們的請求的匹配嚴格程度。
接下來,讓我們建立一個ChatLanguageModel bean,它將根據檢索到的內容產生回應:
@Bean
public ChatLanguageModel chatModel() {
return OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4o-mini")
.build();
}在這個 bean 中,我們使用了gpt-4o-mini模型,但我們總是可以選擇另一個更符合我們要求的模型。
現在,我們將建立一個ArticleBasedAssistant介面。在這裡,我們將定義*answer()*方法,該方法接受文字請求並返回文字回應:
public interface ArticleBasedAssistant {
String answer(String question);
}LangChain4j透過結合配置的語言模型和內容檢索器動態來實現此介面。接下來,讓我們為助手介面建立一個 bean:
@Bean
public ArticleBasedAssistant articleBasedAssistant(ChatLanguageModel chatModel, ContentRetriever contentRetriever) {
return AiServices.builder(ArticleBasedAssistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.build();
}這種設定意味著我們現在可以呼叫assistant.answer(“…”) ,並且在底層嵌入查詢,並從向量儲存中取得相關文件。這些文件在 LLM 提示中用作上下文,並產生並傳回自然語言答案。
5.2. ChatBotController**實作與測試結果**
最後,讓我們建立ChatBotController ,它將GET請求對應到聊天機器人邏輯:
@RestController
public class ChatBotController {
private final ArticleBasedAssistant assistant;
@Autowired
public ChatBotController(ArticleBasedAssistant assistant) {
this.assistant = assistant;
}
@GetMapping("/chat-bot")
public String answer(@RequestParam("question") String question) {
return assistant.answer(question);
}
}在這裡,我們實作了聊天機器人端點,並將其與ArticleBasedAssistant整合。此端點透過問題請求參數接受使用者查詢,將其委託給 ArticleBasedAssistant,並以純文字形式傳回產生的回應。
讓我們呼叫我們的聊天機器人 API 並看看它回應什麼:
@AutoConfigureMockMvc
@SpringBootTest(classes = {ChatBotConfiguration.class, ArticlesRepository.class, ChatBotController.class})
class ChatBotLiveTest {
Logger log = LoggerFactory.getLogger(ChatBotLiveTest.class);
@Autowired
private MockMvc mockMvc;
@Test
void givenChatBotApi_whenCallingGetEndpointWithQuestion_thenExpectedAnswersIsPresent() throws Exception {
String chatResponse = mockMvc
.perform(get("/chat-bot")
.param("question", "Steps to implement Spring boot app and MongoDB"))
.andReturn()
.getResponse()
.getContentAsString();
log.info(chatResponse);
Assertions.assertTrue(chatResponse.contains("Step 1"));
}
}在我們的測試中,我們呼叫了聊天機器人端點並要求它為我們提供創建具有 MongoDB 整合的 Spring Boot 應用程式的步驟。此後,我們檢索並記錄了預期結果。完整的回應也可以在日誌中看到:
To implement a MongoDB Spring Boot Java Book Tracker application, follow these steps. This guide will help you set up a simple CRUD application to manage books, where you can add, edit, and delete book records stored in a MongoDB database.
### Step 1: Set Up Your Environment
1. **Install Java Development Kit (JDK)**:
Make sure you have JDK (Java Development Kit) installed on your machine. You can download it from the [Oracle website](https://www.oracle.com/java/technologies/javase-jdk11-downloads.html) or use OpenJDK.
2. **Install MongoDB**:
Download and install MongoDB from the [MongoDB official website](https://www.mongodb.com/try/download/community). Follow the installation instructions specific to your operating system.
//shortened
6. 結論
在本文中,我們使用 Langchain4j 和 MongoDB Atlas 實作了聊天機器人 Web 應用程式。使用我們的應用程序,我們可以與聊天機器人互動以從下載的文章中獲取資訊。為了進一步改進,我們可以添加查詢預處理並處理模糊查詢。除此之外,我們還可以輕鬆擴展聊天機器人回答問題所基於的資料集。
與往常一樣,程式碼可在 GitHub 上取得。