Elasticsearch入門教學
ElasticSearch是一個高度可擴展的開源搜索引擎並使用REST API,所以您值得擁有。 在本教程中,將介紹開始使用ElasticSearch的一些主要概念。
下載並運行ElasticSearch
ElasticSearch可以從elasticsearch.org下載對應的文件格式,如ZIP和TAR.GZ。下載並提取一個運行它的軟件包之後不會容易得多,需要提前安裝Java運行時環境。
在Windows上運行ElasticSearch
在本文章中,所使用的環境是Windows,所以這裏只介紹在Windows上運行ElasticSearch,可從命令窗口運行位於bin文件夾中的elasticsearch.bat。這將會啓動ElasticSearch在控制檯的前臺運行,這意味着我們可在控制檯中看到運行信息或一些錯誤信息,並可以使用CTRL + C停止或關閉它。
當前版本是: elasticsearch-5.2.0
下載鏈接: http://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.0.zip
把下載好的文件 elasticsearch-5.2.0.zip 解壓到 D:\software\elasticsearch-5.2.0,其目錄結構如下所示 -
啓動 ElasticSearch -
Microsoft Windows [版本 10.0.10586]
(c) 2015 Microsoft Corporation。保留所有權利。
C:\Users\Administrator>d:
D:\>cd software\elasticsearch-5.2.0
D:\software\elasticsearch-5.2.0>cd bin
D:\software\elasticsearch-5.2.0\bin>elasticsearch.bat
[2017-01-28T14:10:32,177][INFO ][o.e.n.Node ] [] initializing ...
[2017-01-28T14:10:32,670][INFO ][o.e.e.NodeEnvironment ] [SnafGWM] using [1] data paths, mounts [[Software (D:)]], net usable_space [61.6gb], net total_space [139gb], spins? [unknown], types [NTFS]
[2017-01-28T14:10:32,686][INFO ][o.e.e.NodeEnvironment ] [SnafGWM] heap size [1.9gb], compressed ordinary object pointers [true]
[2017-01-28T14:10:32,686][INFO ][o.e.n.Node ] node name [SnafGWM] derived from node ID [SnafGWMWRzmfwTKP6VJClA]; set [node.name] to override
[2017-01-28T14:10:32,717][INFO ][o.e.n.Node ] version[5.2.0], pid[9724], build[24e05b9/2017-01-24T19:52:35.800Z], OS[Windows 10/10.0/amd64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_65/25.65-b01]
[2017-01-28T14:10:35,271][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [aggs-matrix-stats]
[2017-01-28T14:10:35,271][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [ingest-common]
[2017-01-28T14:10:35,271][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [language-expression]
[2017-01-28T14:10:35,271][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [language-groovy]
[2017-01-28T14:10:35,271][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [language-mustache]
[2017-01-28T14:10:35,287][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [language-painless]
[2017-01-28T14:10:35,287][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [percolator]
[2017-01-28T14:10:35,288][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [reindex]
[2017-01-28T14:10:35,290][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [transport-netty3]
[2017-01-28T14:10:35,291][INFO ][o.e.p.PluginsService ] [SnafGWM] loaded module [transport-netty4]
[2017-01-28T14:10:35,292][INFO ][o.e.p.PluginsService ] [SnafGWM] no plugins loaded
[2017-01-28T14:10:41,394][INFO ][o.e.n.Node ] initialized
[2017-01-28T14:10:41,397][INFO ][o.e.n.Node ] [SnafGWM] starting ...
[2017-01-28T14:10:42,657][INFO ][o.e.t.TransportService ] [SnafGWM] publish_address {127.0.0.1:9300}, bound_addresses {127.0.0.1:9300}, {[::1]:9300}
[2017-01-28T14:10:46,439][INFO ][o.e.c.s.ClusterService ] [SnafGWM] new_master {SnafGWM}{SnafGWMWRzmfwTKP6VJClA}{vG5mFSENST6eo-yl_O8HuA}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-elected-as-master ([0] nodes joined)
[2017-01-28T14:10:48,628][INFO ][o.e.h.HttpServer ] [SnafGWM] publish_address {127.0.0.1:9200}, bound_addresses {127.0.0.1:9200}, {[::1]:9200}
[2017-01-28T14:10:48,628][INFO ][o.e.n.Node ] [SnafGWM] started
[2017-01-28T14:10:48,928][INFO ][o.e.g.GatewayService ] [SnafGWM] recovered [0] indices into cluster_state在啓動過程中,ElasticSearch的實例運行會佔用大量的內存,所以在這一過程中,電腦會變得比較慢,需要耐心等待,啓動加載完成後電腦就可以正常使用了。
如果您沒有安裝Java運行時或沒有正確配置,應該不會看到像上面的輸出,而是一個消息說「JAVA_HOME環境變量必須設置!「 要解決這個問題,首先下載並安裝Java,其次,確保已正確配置
JAVA_HOME環境變量(或參考 - Java JDK安裝和配置)。
使用REST API與Sense
當ElasticSearch的實例並運行,您可以使用localhost:9200,基於JSON的REST API與ElasticSearch進行通信。使用任何HTTP客戶端來通信。在ElasticSearch自己的文檔中,所有示例都使用curl。 但是,當使用API時也可使用圖形客戶端(如Fiddler或RESTClient),這樣操作起更方便直觀一些。
更方便的是Chrome插件Sense。 Sense提供了一個專門用於使用ElasticSearch的REST API的簡單用戶界面。 它還具有許多方便的功能,例如:ElasticSearch的查詢語法的自動完成功能以及curl格式的複製和粘貼請求,從而可以方便地在文檔中運行示例。
我們將在本教程中使用sense來執行curl請求,建議安裝Sense並使用它學習後續文章內容。
安裝完成後,在Chrome的右上角找到Sense的圖標。 第一次單擊它運行Sense時,會爲您準備一個非常簡單的示例請求。如下圖所示 -
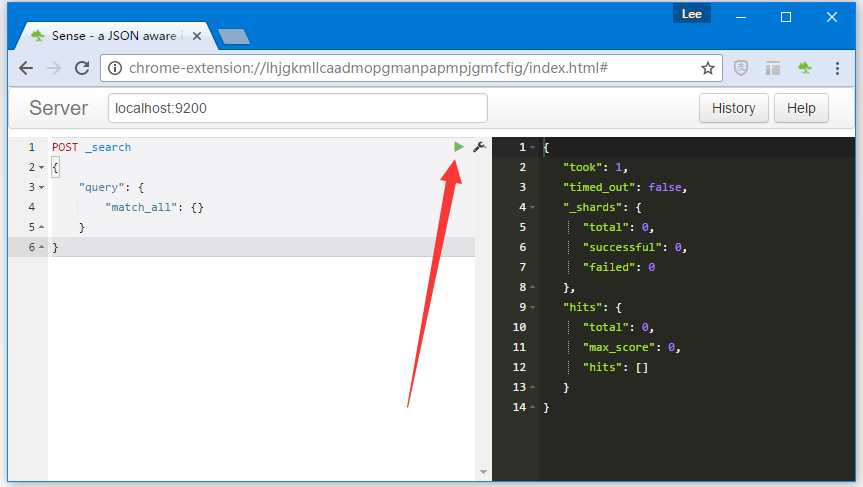
上述請求將執行最簡單的搜索查詢,匹配服務器上所有索引中的所有文檔。針對ElasticSearch運行,Sense提供的最簡單的查詢,在響應結果的數據中並沒有查詢到任何數據,因爲沒有任何索引。如下所示 -
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
}
}下一步我們來學習添加一些數據和索引,來修復這個問題。
文檔管理(CRUD)
想要使用ElasticSearch,用於搜索第一步就是使用一些數據填充來索引,CRUD表「創建」或者「索引」。我們還將學習如何更新,讀取和刪除文檔。
創建索引
在ElasticSearch索引中,對應於CRUD中的「創建」和「更新」 - 如果對具有給定類型的文檔進行索引,並且要插入原先不存在的ID。 如果具有相同類型和ID的文檔已存在,則會被覆蓋。
要索引第一個JSON對象,我們對REST API創建一個PUT請求到一個由索引名稱,類型名稱和ID組成的URL。 也就是:http://localhost:9200/<index>/<type>/[<id>]。
索引和類型是必需的,而id部分是可選的。如果不指定ID,ElasticSearch會爲我們生成一個ID。 但是,如果不指定id,應該使用HTTP的POST而不是PUT請求。
索引名稱是任意的。如果服務器上沒有此名稱的索引,則將使用默認配置來創建一個索引。
至於類型名稱,它也是任意的。 它有幾個用途,包括:
- 每種類型都有自己的ID空間。
- 不同類型具有不同的映射(「模式」,定義屬性/字段應如何編制索引)。
- 搜索多種類型是可以的,並且也很常見,但很容易搜索一種或多種指定類型。
現在我們來索引一些內容! 可以把任何東西放到索引中,只要它可以表示爲單個JSON對象。 在本教程中,使用索引和搜索電影的一個示例。這是一個經典的電影對象信息:
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}要創建一個索引,這裏使用索引的名稱爲「movies」,類型名稱(「movie」)和id(「1」),並按照上述模式使用JSON對象在正文中進行請求。
curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}'可以使用curl來執行它,也可以使用Sense。這裏使用Sense,可以自己填充URL,方法和請求正文,或者您以複製上述curl示例,將光標置於Sense中的正文字段中寫入上面的Json對象,然後按點擊綠色小箭頭來執行創建索引操作。如下圖所示 -
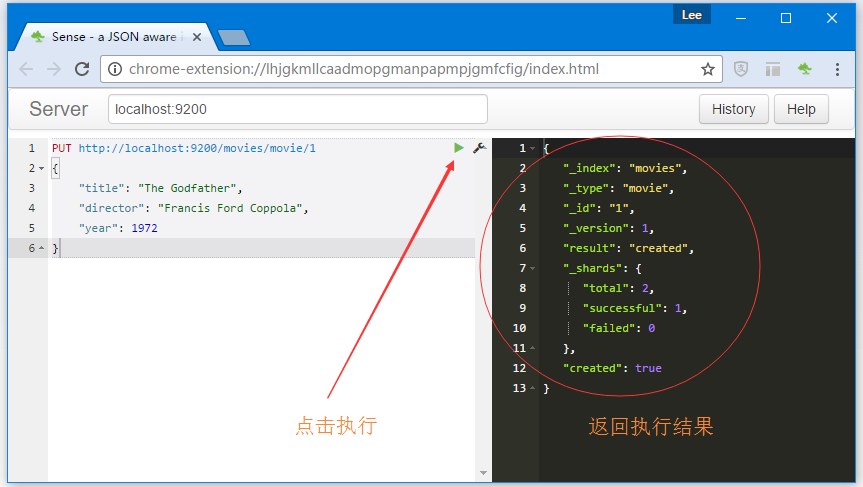
執行請求後,可以看到接收到來自ElasticSearch響應的JSON對象。如下所示 -
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}響應對象包含有關索引操作的信息,例如它是否成功(「ok」)和文檔ID,如果不指定則ElasticSearch會自己生成一個。
如果運行Sense提供的默認搜索請求(可以使用Sense中的「歷史記錄」按鈕訪問,因爲確實已執行它)過了,就會看到返回有數據的結果。
{
"took": 146,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_score": 1,
"_source": {
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}
}
]
}
}在上面返回結果中,看到的是搜索結果而不是錯誤或是空的結果。
更新索引
現在,在索引中有了一部電影信息,接下來來了解如何更新它,添加一個類型列表。要做到這一點,只需使用相同的ID索引它。使用與之前完全相同的索引請求,但類型擴展了JSON對象。
curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'ElasticSearch的響應結果與前面的大體上一樣,但有一點區別,結果對象中的_version屬性的值爲2,而不是1。響應結果如下 -
{
"_index": "movies",
"_type": "movie",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}版本號(_version)可用於跟蹤文檔已編入索引的次數。它的主要目的是允許樂觀的併發控制,因爲可以在索引請求中提供一個版本,如果提供的版本高於索引中的版本,ElasticSearch將只覆蓋文檔內容,ID值不變,版本號自動添加。
由ID獲取文檔/索引
上面已經學習了索引新文檔以及更新存在的文檔。還看到了一個簡單搜索請求的示例。如果只是想檢索一個具有已知ID的索引,一個方法是搜索索引中的文檔。另一個簡單而快速的方法是通過ID,使用GET來檢索它。
簡單的做法是向同一個URL發出一個GET請求,URL的ID部分是強制性的。通過ID從ElasticSearch中檢索文檔可發出URL的GET請求:http://localhost:9200/<index>/<type>/<id>。
使用以下請求嘗試獲取電影信息:
curl -XGET "http://localhost:9200/movies/movie/1" -d''執行結果如下所示 -
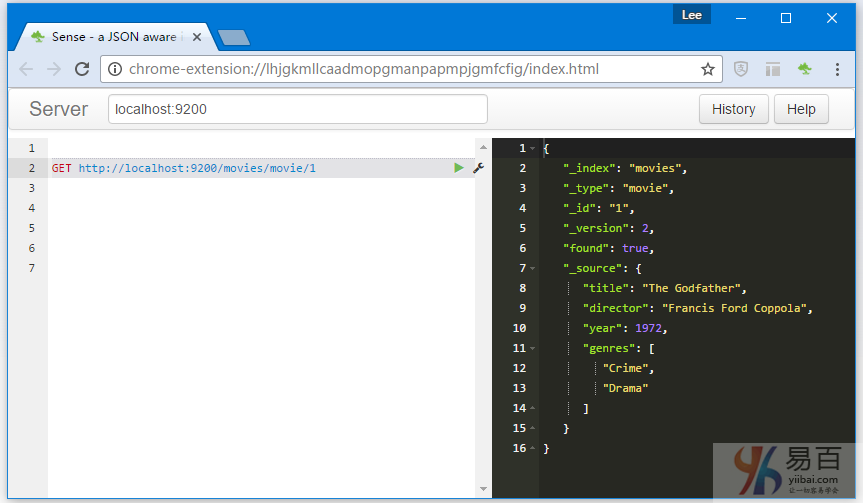
正如下圖所看到的,結果對象包含與索引時所看到的類似的元數據,如索引,類型和版本信息。 最後最重要的是,它有一個名稱爲「_source」的屬性,它包含實際獲取的文檔信息。
關於GET沒有什麼可說的,因爲它很簡單,繼續最後刪除操作。
刪除文檔
爲了通過ID從索引中刪除單個指定的文檔,使用與獲取索引文檔相同的URL,只是這裏將HTTP方法更改爲DELETE。
curl -XDELETE "http://localhost:9200/movies/movie/1" -d''響應對象包含元數據方面的一些常見數據字段,以及名爲「_found」的屬性,表示文檔確實已找到並且操作成功。
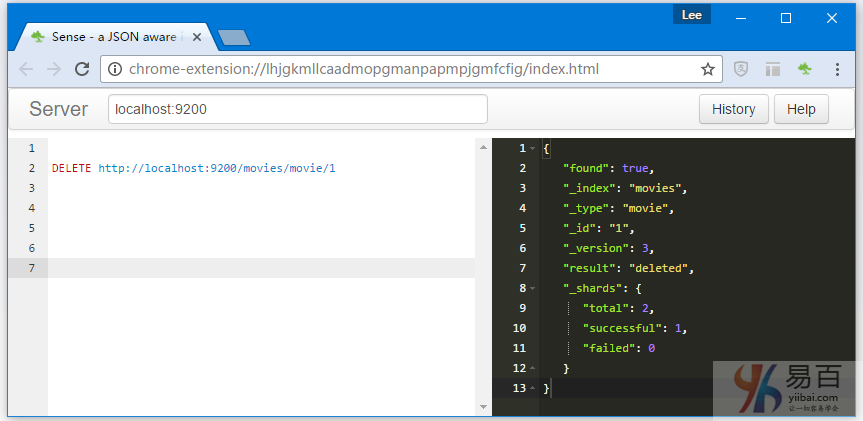
在執行
DELETE調用後切換回GET,可以驗證文檔是否確實已刪除。
搜索
在前面,已經介紹了在ElasticSearch索引中處理數據的基礎知識,現在是時候進行核心功能的學習了。考慮到之前我們刪除索引中的所有文檔,所以,在進行搜索學習之前,需要一些添加一些示例數據。使用以下這些請求和數據對象來創建索引。
curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'
curl -XPUT "http://localhost:9200/movies/movie/2" -d'
{
"title": "Lawrence of Arabia",
"director": "David Lean",
"year": 1962,
"genres": ["Adventure", "Biography", "Drama"]
}'
curl -XPUT "http://localhost:9200/movies/movie/3" -d'
{
"title": "To Kill a Mockingbird",
"director": "Robert Mulligan",
"year": 1962,
"genres": ["Crime", "Drama", "Mystery"]
}'
curl -XPUT "http://localhost:9200/movies/movie/4" -d'
{
"title": "Apocalypse Now",
"director": "Francis Ford Coppola",
"year": 1979,
"genres": ["Drama", "War"]
}'
curl -XPUT "http://localhost:9200/movies/movie/5" -d'
{
"title": "Kill Bill: Vol. 1",
"director": "Quentin Tarantino",
"year": 2003,
"genres": ["Action", "Crime", "Thriller"]
}'
curl -XPUT "http://localhost:9200/movies/movie/6" -d'
{
"title": "The Assassination of Jesse James by the Coward Robert Ford",
"director": "Andrew Dominik",
"year": 2007,
"genres": ["Biography", "Crime", "Drama"]
}'值得指出的是,ElasticSearch具有和端點(_bulk)用於用單個請求索引多個文檔,但是這超出了本教程的範圍,這裏只保持簡單,使用六個單獨的請求學習。
_search端點
現在已經把一些電影信息放入了索引,可以通過搜索看看是否可找到它們。 爲了使用ElasticSearch進行搜索,我們使用_search端點,可選擇使用索引和類型。也就是說,按照以下模式向URL發出請求:<index>/<type>/_search。其中,index和type都是可選的。
換句話說,爲了搜索電影,可以對以下任一URL進行POST請求:
- http://localhost:9200/_search - 搜索所有索引和所有類型。
- http://localhost:9200/movies/_search - 在電影索引中搜索所有類型
- http://localhost:9200/movies/movie/_search - 在電影索引中顯式搜索電影類型的文檔。
因爲我們只有一個單一的索引和單一的類型,所以怎麼使用都不會有什麼問題。爲了簡潔起見使用第一個URL。
搜索請求正文和ElasticSearch查詢DSL
如果只是發送一個請求到上面的URL,我們會得到所有的電影信息。爲了創建更有用的搜索請求,還需要向請求正文中提供查詢。 請求正文是一個JSON對象,除了其它屬性以外,它還要包含一個名稱爲「query」的屬性,這就可使用ElasticSearch的查詢DSL。
{
"query": {
//Query DSL here
}
}你可能想知道查詢DSL是什麼。它是ElasticSearch自己基於JSON的域特定語言,可以在其中表達查詢和過濾器。想象ElasticSearch它像關係數據庫的SQL。這裏是ElasticSearch自己的文檔解釋它的一部分(英文好自己擼吧):
Think of the Query DSL as an AST of queries. Certain queries can contain other queries (like the bool query), other can contain filters (like the constant_score), and some can contain both a query and a filter (like the filtered). Each of those can contain any query of the list of queries or any filter from the list of filters, resulting in the ability to build quite complex (and interesting) queries. see more: http://www.elasticsearch.org/guide/reference/query-dsl/
基本自由文本搜索
查詢DSL具有一長列不同類型的查詢可以使用。 對於「普通」自由文本搜索,最有可能想使用一個名稱爲「查詢字符串查詢」。
查詢字符串查詢是一個高級查詢,有很多不同的選項,ElasticSearch將解析和轉換爲更簡單的查詢樹。如果忽略了所有的可選參數,並且只需要給它一個字符串用於搜索,它可以很容易使用。
現在嘗試在兩部電影的標題中搜索有「kill」這個詞的電影信息:
curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"query_string": {
"query": "kill"
}
}
}'執行上面的請求並查看結果,如下所示 -
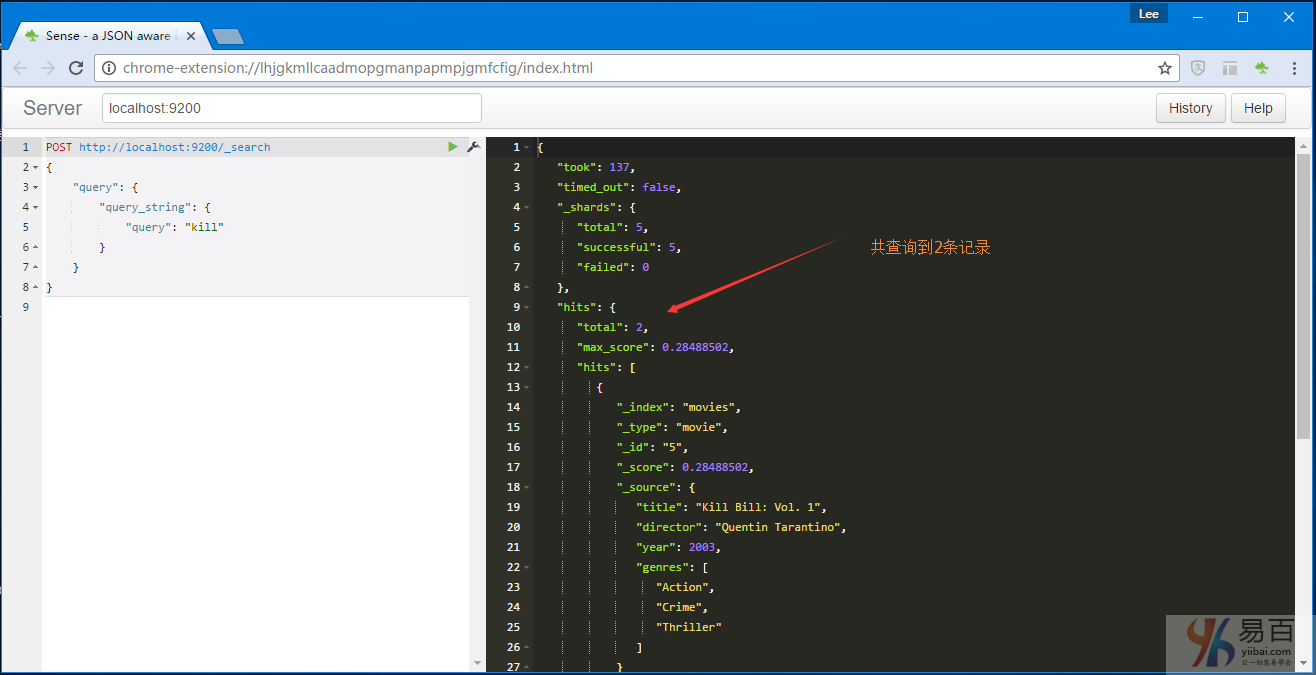
正如預期的,得到兩個命中結果,每個電影的標題中都帶有「kill」單詞。再看看另一種情況,在特定字段中搜索。
指定搜索的字段
在前面的例子中,使用了一個非常簡單的查詢,一個只有一個屬性「query」的查詢字符串查詢。 如前所述,查詢字符串查詢有一些可以指定設置,如果不使用,它將會使用默認的設置值。
這樣的設置稱爲「fields」,可用於指定要搜索的字段列表。如果不使用「fields」字段,ElasticSearch查詢將默認自動生成的名爲「_all」的特殊字段,來基於所有文檔中的各個字段匹配搜索。
爲了做到這一點,修改以前的搜索請求正文,以便查詢字符串查詢有一個fields屬性用來要搜索的字段數組:
curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"query_string": {
"query": "ford",
"fields": ["title"]
}
}
}'執行上面查詢它,看看會有什麼結果(應該只匹配到 1 行數據):
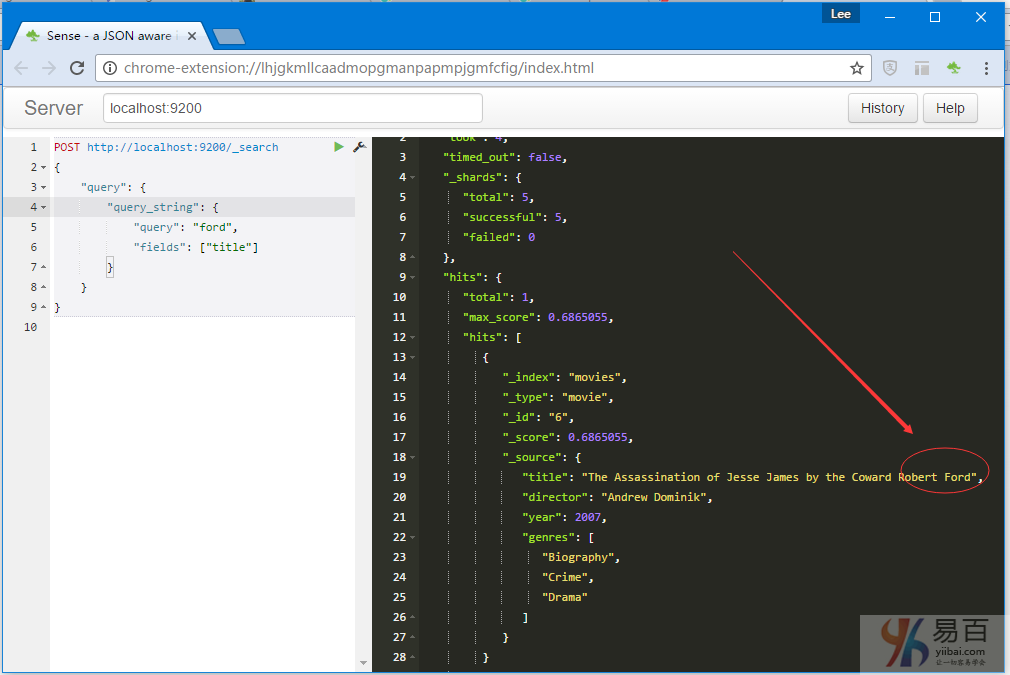
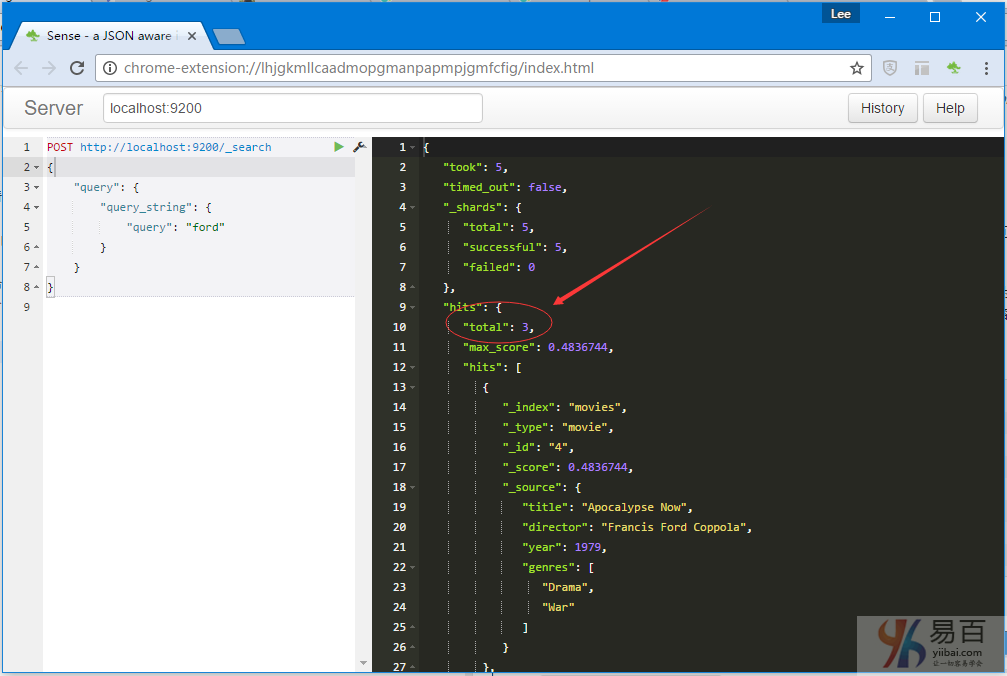
正如預期的得到一個命中,電影的標題中的單詞「ford」。現在,從查詢中移除fields屬性,應該能匹配到 3 行數據:
過濾
前面已經介紹了幾個簡單的自由文本搜索查詢。現在來看看另一個示例,搜索「drama」,不明確指定字段,如下查詢 -
curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"query_string": {
"query": "drama"
}
}
}'因爲在索引中有五部電影在_all字段(從類別字段)中包含單詞「drama」,所以得到了上述查詢的5個命中。 現在,想象一下,如果我們想限制這些命中爲只是1962年發佈的電影。要做到這點,需要應用一個過濾器,要求「year」字段等於1962。
要添加過濾器,修改搜索請求正文,以便當前的頂級查詢(查詢字符串查詢)包含在過濾的查詢中:
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
//Filter to apply to the query
}
}
}
}過濾的查詢是具有兩個屬性(query和filter)的查詢。執行時,它使用過濾器過濾查詢的結果。要完成這樣的查詢還需要添加一個過濾器,要求year字段的值爲1962。
ElasticSearch查詢DSL有各種各樣的過濾器可供選擇。對於這個簡單的情況,某個字段應該匹配一個特定的值,一個條件過濾器就能很好地完成工作。
"filter": {
"term": { "year": 1962 }
}完整的搜索請求如下所示:
curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
"term": { "year": 1962 }
}
}
}
}'當執行上面請求,只得到兩個命中,這個兩個命中的數據的 year 字段的值都是等於 1962。
無需查詢即可進行過濾
在上面的示例中,使用過濾器限制查詢字符串查詢的結果。如果想要做的是應用一個過濾器呢? 也就是說,我們希望所有電影符合一定的標準。
在這種情況下,我們仍然在搜索請求正文中使用「query」屬性。但是,我們不能只是添加一個過濾器,需要將它包裝在某種查詢中。
一個解決方案是修改當前的搜索請求,替換查詢字符串 query 過濾查詢中的match_all查詢,這是一個查詢,只是匹配一切。類似下面這個:
curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"filtered": {
"query": {
"match_all": {
}
},
"filter": {
"term": { "year": 1962 }
}
}
}
}'另一個更簡單的方法是使用常數分數查詢:
curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"constant_score": {
"filter": {
"term": { "year": 1962 }
}
}
}
}'