Hive教學
Hive是一個數據倉庫基礎工具在Hadoop中用來處理結構化數據。它架構在Hadoop之上,總歸爲大數據,並使得查詢和分析方便。並提供簡單的sql查詢功能,可以將sql語句轉換爲MapReduce任務進行運行。
術語「大數據」是大型數據集,其中包括體積龐大,高速,以及各種由與日俱增的數據的集合。使用傳統的數據管理系統,它是難以加工大型數據。因此,Apache軟件基金會推出了一款名爲Hadoop的解決大數據管理和處理難題的框架。
Hadoop
Hadoop是一個開源框架來存儲和處理大型數據在分佈式環境中。它包含兩個模塊,一個是MapReduce,另外一個是Hadoop分佈式文件系統(HDFS)。
MapReduce:它是一種並行編程模型在大型集羣普通硬件可用於處理大型結構化,半結構化和非結構化數據。
HDFS:Hadoop分佈式文件系統是Hadoop的框架的一部分,用於存儲和處理數據集。它提供了一個容錯文件系統在普通硬件上運行。
Hadoop生態系統包含了用於協助Hadoop的不同的子項目(工具)模塊,如Sqoop, Pig 和 Hive。
Sqoop: 它是用來在HDFS和RDBMS之間來回導入和導出數據。
Pig: 它是用於開發MapReduce操作的腳本程序語言的平臺。
Hive: 它是用來開發SQL類型腳本用於做MapReduce操作的平臺。
注:有多種方法來執行MapReduce作業:
- 傳統的方法是使用Java MapReduce程序結構化,半結構化和非結構化數據。
- 針對MapReduce的腳本的方式,使用Pig來處理結構化和半結構化數據。
- Hive查詢語言(HiveQL或HQL)採用Hive爲MapReduce的處理結構化數據。
Hive是什麼?
Hive是一個數據倉庫基礎工具在Hadoop中用來處理結構化數據。它架構在Hadoop之上,總歸爲大數據,並使得查詢和分析方便。
最初,Hive是由Facebook開發,後來由Apache軟件基金會開發,並作爲進一步將它作爲名義下Apache Hive爲一個開源項目。它用在好多不同的公司。例如,亞馬遜使用它在 Amazon Elastic MapReduce。
Hive 不是
- 一個關係數據庫
- 一個設計用於聯機事務處理(OLTP)
- 實時查詢和行級更新的語言
Hiver特點
- 它存儲架構在一個數據庫中並處理數據到HDFS。
- 它是專爲OLAP設計。
- 它提供SQL類型語言查詢叫HiveQL或HQL。
- 它是熟知,快速,可擴展和可擴展的。
Hive架構
下面的組件圖描繪了Hive的結構:
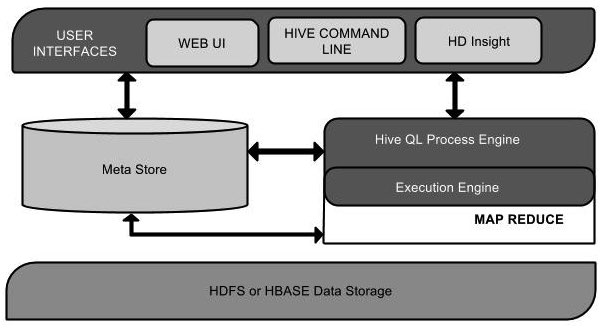
該組件圖包含不同的單元。下表描述每個單元:
單元名稱
操作
用戶接口/界面
Hive是一個數據倉庫基礎工具軟件,可以創建用戶和HDFS之間互動。用戶界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服務器)。
元存儲
Hive選擇各自的數據庫服務器,用以儲存表,數據庫,列模式或元數據表,它們的數據類型和HDFS映射。
HiveQL處理引擎
HiveQL類似於SQL的查詢上Metastore模式信息。這是傳統的方式進行MapReduce程序的替代品之一。相反,使用Java編寫的MapReduce程序,可以編寫爲MapReduce工作,並處理它的查詢。
執行引擎
HiveQL處理引擎和MapReduce的結合部分是由Hive執行引擎。執行引擎處理查詢併產生結果和MapReduce的結果一樣。它採用MapReduce方法。
HDFS 或 HBASE
Hadoop的分佈式文件系統或者HBASE數據存儲技術是用於將數據存儲到文件系統。
Hive工作原理
下圖描述了Hive 和Hadoop之間的工作流程。
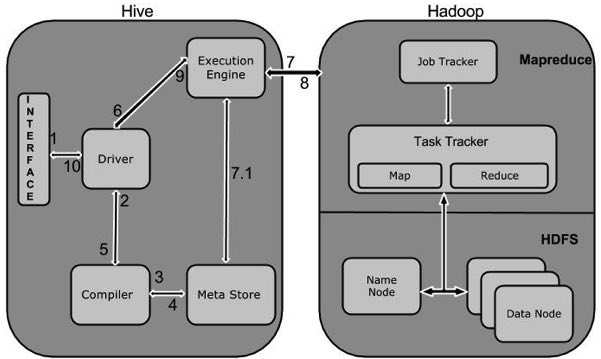
下表定義Hive和Hadoop框架的交互方式:
Step No.
操作
1
Execute Query
Hive接口,如命令行或Web UI發送查詢驅動程序(任何數據庫驅動程序,如JDBC,ODBC等)來執行。
2
Get Plan
在驅動程序幫助下查詢編譯器,分析查詢檢查語法和查詢計劃或查詢的要求。
3
Get Metadata
編譯器發送元數據請求到Metastore(任何數據庫)。
4
Send Metadata
Metastore發送元數據,以編譯器的響應。
5
Send Plan
編譯器檢查要求,並重新發送計劃給驅動程序。到此爲止,查詢解析和編譯完成。
6
Execute Plan
驅動程序發送的執行計劃到執行引擎。
7
Execute Job
在內部,執行作業的過程是一個MapReduce工作。執行引擎發送作業給JobTracker,在名稱節點並把它分配作業到TaskTracker,這是在數據節點。在這裏,查詢執行MapReduce工作。
7.1
Metadata Ops
與此同時,在執行時,執行引擎可以通過Metastore執行元數據操作。
8
Fetch Result
執行引擎接收來自數據節點的結果。
9
Send Results
執行引擎發送這些結果值給驅動程序。
10
Send Results
驅動程序將結果發送給Hive接口。