JPA ORM組件
最現代的應用程序使用關係型數據庫來存儲數據。最近,許多廠商改用對象數據庫,以減少其對數據的維護負擔。這意味着對象數據庫或對象關係技術正在存儲,檢索,更新和維護數據的照顧。這個對象關係型技術的核心部分是映射orm.xml中的文件。隨着XML不需要編譯,可以很容易地進行修改多個數據源較少的管理。
對象關係映射
對象關係映射(ORM)簡要地告訴什麼是ORM以及它是如何工作。 ORM是從對象類型的數據隱蔽到關係型,反之亦然編程能力。
ORM主要特徵是映射或綁定一個目的是它的數據庫中的數據。而映射,我們要考慮的任何其他表中的數據,數據的類型,並具有自一個或多個實體的關係。
高級功能
慣用的持久性:它使您能夠編寫使用面向對象的類持久性類。
高性能:它有許多抓取技術和充滿希望的鎖定技術。
可靠的:它是高度穩定的,被很多專業程序員。
ORM架構
在ORM架構如下所示。
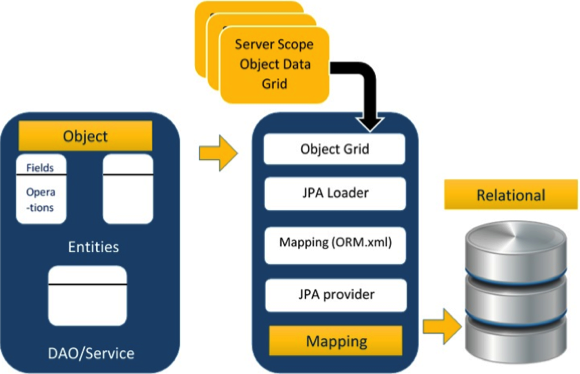
在上述體系結構解釋瞭如何對象數據存儲到關係數據庫中的三個階段。
第1階段
第一階段,命名爲對象數據階段,包括POJO類,服務接口和類。它是主要的業務組件層,其具有業務邏輯操作和屬性。
例如,讓我們舉個員工數據庫的架構。
Employee POJO類包含屬性,如ID,姓名,工資和標識。它也包含類似屬性setter和getter方法。
Employee DAO/服務類包含服務方法,如建立員工,發現員工和刪除員工。
第2階段
第二階段,稱爲映射或持久性的階段,包括JPA提供者,映射文件(orm.xml),JPA裝載器和對象網格。
JPA提供者:這是一個包含了JPA(javax.persistence)供應的產品。例如EclipseLink,Toplink,Hibernate等。
映射文件:映射文件(orm.xml中)包含在關係數據庫中的一個POJO類的數據和數據之間的映射配置。
JPA裝載器:在JPA加載器的工作原理就像一個高速緩衝存儲器。它可以加載關係網格數據。它的工作原理類似數據庫的副本與服務類POJO數據(POJO類的屬性)進行交互。
對象網格:它是可存儲的關係數據的副本,如高速緩衝存儲器的臨時位置。對數據庫的所有查詢首先被實現在對象網格的數據。只有提交它纔會影響到主數據庫。
第3階段
第三階段是關係數據相關。它包含在邏輯上連接到所述業務組件的關係數據。如上所討論的,僅當業務組件提交該數據,它被存儲到數據庫中的物理。在此之前,已修改的數據被存儲在高速緩衝存儲器作爲一個網格格式。在獲取數據的過程和存儲數據是相同的。
上述三個階段的編程交互的機制被稱爲對象關係映射。
Mapping.xml
mapping.xml文件指示JPA的供應者來映射實體類與數據庫表。
讓我們以Employee實體包含四個屬性的一個例子。POJO類Employee實體的命名爲:Employee.java,如下:
public class Employee
{
private int eid;
private String ename;
private double salary;
private String deg;
public Employee(int eid, String ename, double salary, String deg)
{
super( );
this.eid = eid;
this.ename = ename;
this.salary = salary;
this.deg = deg;
}
public Employee( )
{
super();
}
public int getEid( )
{
return eid;
}
public void setEid(int eid)
{
this.eid = eid;
}
public String getEname( )
{
return ename;
}
public void setEname(String ename)
{
this.ename = ename;
}
public double getSalary( )
{
return salary;
}
public void setSalary(double salary)
{
this.salary = salary;
}
public String getDeg( )
{
return deg;
}
public void setDeg(String deg)
{
this.deg = deg;
}
}
上面的代碼是Employee實體POJO類。它包含四個屬性eid, ename,salary, 和 deg。考慮這些屬性爲表的字段,並且eid作爲該表的主鍵。現在,我們要設計Hibernate映射文件了。映射文件名爲 mapping.xml 如下:
上述腳本用於與數據庫表的映射實體類。在該文件中
: 標籤定義的模式定義,允許實體標記爲XML文件。 : 標籤提供了有關應用程序的描述。 : 標籤定義要轉換成數據庫表中的實體類。屬性類定義了POJO實體類的名稱。 -
: 標籤定義的表名。如果想有兩個類相同的名稱以及該表中,則該標籤是沒有必要的。
: 標籤定義的屬性(在表中的字段)。 : 標記定義表中的主鍵。在 標記定義瞭如何將主鍵值賦值,如Automatic, Manual或者使用 Sequence。 : 標籤用於定義其餘屬性在表中。 : 標籤被用來在表中定義用戶定義表的字段名。 註解
一般的XML文件用於配置特定的組件,或者映射兩種不同規格的組件。在我們的例子中,我們要分別保持在一個框架的XML文件。這意味着在寫一個映射的XML文件,我們需要比較用mapping.xml文件實體標籤的POJO類的屬性。
這裏是解決方案。在類定義中,我們可以使用註釋寫配置的一部分。註解用於類,屬性和方法。註釋以'@'符號在類,屬性或方法的註釋中聲明之前。 JPA的所有批註在javax.persistence包定義。
在這裏,在我們的實例中使用的註釋列表如下。
註解
描述
@Entity
聲明類爲實體或表。
@Table
聲明表名。
@Basic
指定非約束明確的各個字段。
@Embedded
指定類或它的值是一個可嵌入的類的實例的實體的屬性。
@Id
指定的類的屬性,用於識別(一個表中的主鍵)。
@GeneratedValue
指定如何標識屬性可以被初始化,例如自動,手動,或從序列表中獲得的值。
@Transient
指定的屬性,它是不持久的,即,該值永遠不會存儲在數據庫中。
@Column
指定持久屬性欄屬性。
@SequenceGenerator
指定在@GeneratedValue註解中指定的屬性的值。它創建了一個序列。
@TableGenerator
指定在@GeneratedValue批註指定屬性的值發生器。它創造了的值生成的表。
@AccessType
這種類型的註釋用於設置訪問類型。如果設置@AccessType(FIELD),然後進入FIELD明智的。如果設置@AccessType(PROPERTY),然後進入屬性發生明智的。
@JoinColumn
指定一個實體組織或實體的集合。這是用在多對一和一對多關聯。
@UniqueConstraint
指定的字段和用於主要或輔助表的唯一約束。
@ColumnResult
參考使用select子句的SQL查詢中的列名。
@ManyToMany
定義了連接表之間的多對多一對多的關係。
@ManyToOne
定義了連接表之間的多對一的關係。
@OneToMany
定義了連接表之間存在一個一對多的關係。
@OneToOne
定義了連接表之間有一個一對一的關係。
@NamedQueries
指定命名查詢的列表。
@NamedQuery
指定使用靜態名稱的查詢。
Java Bean標準
Java類封裝了實例的值及其行爲爲對象稱爲一個單元。 Java Bean是一個臨時的存儲和可重用的組件或對象。它是有一個默認的構造函數和getter和setter方法來初始化實例序列化的類單獨的屬性。
Bean約定
bean包含其默認構造函數或包含序列化實例的文件。因此,一個bean可以實例化另一個bean。
bean屬性可以被隔離成布爾屬性或者非布爾屬性。
非布爾屬性包含getter和setter方法。
布爾屬性包含setter和方法。
任何字段的getter方法應從小字母get(Java方法的公約)開始,之後使用大寫字母開頭的字段名。例如,字段名爲salary,因此這一字段的getter方法爲getSalary()。
任何屬性的setter方法應該先從小字母的集合(Java方法公約)開始,繼續以大寫字母,參數值設置爲字段開頭的字段名。例如,字段名爲salary,因此這一字段的setter方法是setSalary(double sal )。
對於布爾型屬性,方法是檢查它是否是 true 或 false。例如,Boolean屬性爲空,則該字段的就是方法isEmpty()。