PDFBox分割PDF文檔
在前一章中,我們已經看到了如何將JavaScript添加到PDF文檔。 現在來學習如何將給定的PDF文檔分成多個文檔。
分割PDF文檔中的頁面
可以使用Splitter類將給定的PDF文檔分割爲多個PDF文檔。 該類用於將給定的PDF文檔分成幾個其他文檔。
以下是拆分現有PDF文檔的步驟
第1步:加載現有的PDF文檔
使用PDDocument類的靜態方法load()加載現有的PDF文檔。 此方法接受一個文件對象作爲參數,因爲這是一個靜態方法,可以使用類名稱調用它,如下所示。
File file = new File("path of the document")
PDDocument document = PDDocument.load(file);第2步:實例化Splitter類
這個Splitter類包含了分割給定的PDF文檔的方法,因此實例化這個類,如下所示。
Splitter splitter = new Splitter();第3步:分割PDF文檔
使用Splitter類的Split()方法來分割給定的文檔。 該方法接受PDDocument類的一個對象作爲參數。
List<PDDocument> Pages = splitter.split(document);split()方法將給定文檔的每個頁面分割爲單獨的文檔,並以列表的形式返回所有這些文檔。
第4步:創建一個迭代器對象
要遍歷文檔列表,需要獲取上述步驟中獲取的列表的迭代器對象,使用listIterator()方法獲取列表的迭代器對象,如下所示。
Iterator<PDDocument> iterator = Pages.listIterator();第5步:關閉文檔
最後,使用PDDocument類的close()方法關閉文檔,如下所示。
document.close();示例
假設在目錄:F:\worksp\pdfbox 中有一個名稱爲mypdf.pdf的PDF文檔,並且該文檔包含兩個頁面 - 一個頁面包含圖像,另一個頁面包含文本,如下所示。
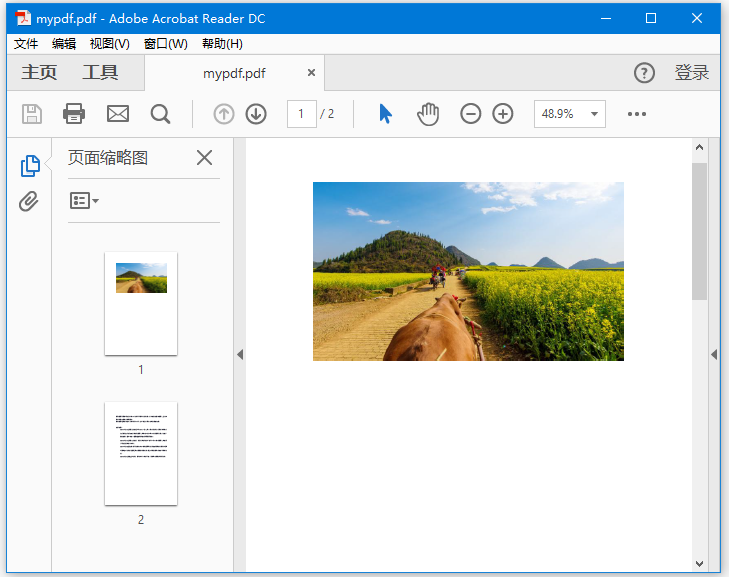
這個例子演示瞭如何分割上面提到的PDF文檔。 在這裏,將把名稱爲mypdf.pdf的PDF文檔分成兩個不同的文檔:sample1.pdf和sample2.pdf。 將此代碼保存在名爲SplitPages.java的文件中。
package com.yiibai;
import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Iterator;
public class SplitPages {
public static void main(String[] args) throws IOException {
//Loading an existing PDF document
File file = new File("F:/worksp/pdfbox/mypdf.pdf");
PDDocument document = PDDocument.load(file);
//Instantiating Splitter class
Splitter splitter = new Splitter();
//splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
//Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
//Saving each page as an individual document
int i = 1;
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
pd.save("F:/worksp/pdfbox/sample"+ i +".pdf");
i = i + 1;
}
System.out.println("Multiple PDF’s created");
document.close();
}
}執行上面示例代碼,得到以下結果 -
Multiple PDF’s created生成的兩個文件,打開效果如下 -
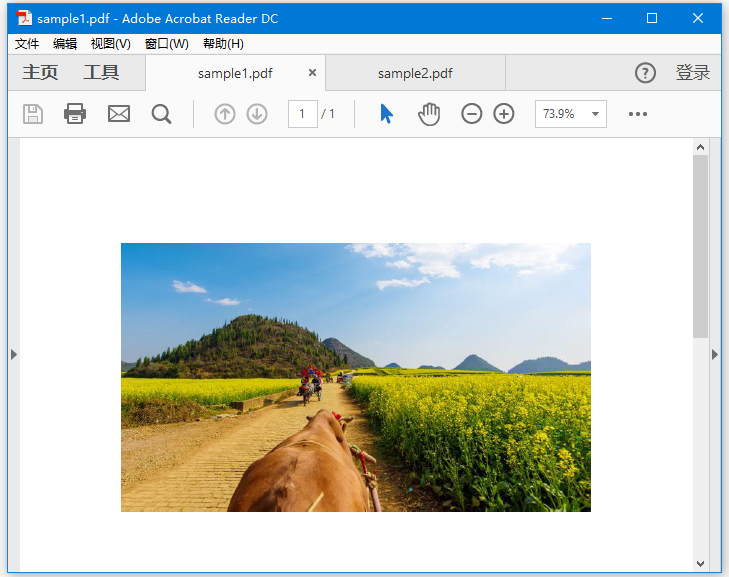
第二個PDF文件: