Cassandra的架構
Cassandra旨在處理多個節點之間的大數據工作負載,而無需擔心單點故障。 它在其節點之間具有對等分佈式系統,數據分佈在集羣中的所有節點上。
- 在Cassandra中,每個節點是獨立的,同時與其他節點互連。 集羣中的所有節點都扮演着相同的角色。
- 集羣中的每個節點都可以接受讀取和寫入請求,而不管數據實際位於集羣中的位置。
- 在一個節點發生故障的情況下,可以從網絡中的其他節點提供讀/寫請求。
Cassandra中的數據複製
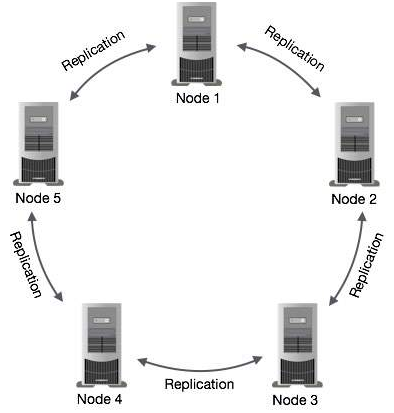
在Cassandra中,集羣中的節點作爲給定數據片段的副本。 如果某些節點以超時值響應,Cassandra會將最新的值返回給客戶端。 返回最新值後,Cassandra會在後臺執行讀取修復,以更新舊值。
請參閱以下圖示,以瞭解Cassandra如何在集羣中的節點之間使用數據複製的原理圖,以確保沒有單點故障。
Cassandra的組成部分
Cassandra的主要組成部分主要有:
- **節點(Node)**:Cassandra節點是存儲數據的地方。
- **數據中心(Data center)**:數據中心是相關節點的集合。
- **集羣(Cluster)**:集羣是包含一個或多個數據中心的組件。
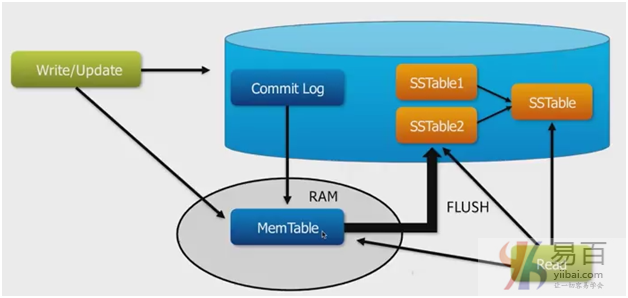
- **提交日誌(Commit log)**:在Cassandra中,提交日誌是一個崩潰恢復機制。 每個寫入操作都將寫入提交日誌。
- **存儲表(Mem-table)**:內存表是內存駐留的數據結構。 提交日誌後,數據將被寫入內存表。 有時,對於單列系列,將有多個內容表。
- SSTable:當內容達到閾值時,它是從內存表刷新數據的磁盤文件。
- **布魯姆過濾器(Bloom filter)**:這些只是快速,非確定性的,用於測試元素是否是集合成員的算法。 它是一種特殊的緩存。 每次查詢後都會訪問Bloom過濾器。
Cassandra查詢語言
Cassandra查詢語言(CQL)用於通過其節點訪問Cassandra。 CQL將數據庫(Keyspace)視爲表的容器。 程序員使用cqlsh:提示使用CQL或單獨的應用程序語言驅動程序。
客戶端可以接近任何節點進行讀寫操作。 該節點(協調器)在客戶機和保存數據的節點之間扮演代理。
寫操作
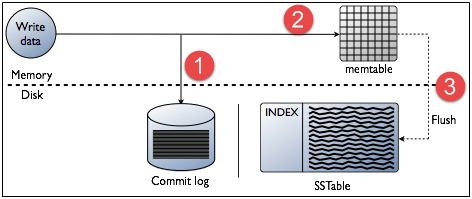
節點的每個寫入活動都由寫入節點的提交日誌捕獲。 之後,數據將被捕獲並存儲在內存表中。 每當內存表已滿時,數據將被寫入SStable數據文件。 所有寫入在整個集羣中自動分區和複製。 Cassandra定期整合SSTables,丟棄不必要的數據。
讀操作
在讀操作中,Cassandra從mem-table中獲取值,並檢查bloom過濾器以找到包含所需數據的適當SSTable。
有三種類型的讀請求被協調者發送給副本。
- 直接請求
- 摘要要求
- 讀修復請求
協調器發送的直接請求到副本中的一個。 之後,協調器將摘要請求發送到由一致性級別指定的副本數,並檢查返回的數據是否是更新的數據。
之後,協調器將所有剩餘的副本發送摘要請求。 如果任何節點發出過期值,後臺讀修復請求將更新該數據。 這個過程稱爲讀修復機制。