MongoDB快速入門
MongoDB是一個跨平臺,面向文檔的數據庫,提供高性能,高可用性和易於擴展。MongoDB是工作在集合和文檔上一種概念。
數據數
數據庫是一個集合的物理容器。每個數據庫獲取其自己設定在文件系統上的文件。一個單一的MongoDB服務器通常有多個數據庫。
集合
集合是一組MongoDB的文件。它與一個RDBMS表是等效的。一個集合存在於數據庫中。集合不強制執行模式。集合中的文檔可以有不同的字段。通常情況下,在一個集合中的所有文件都是類似或相關目的。
文檔
文檔是一組鍵值對。文檔具有動態模式。動態模式是指,在同一個集合的文件不必具有相同一組集合的文檔字段或結構,並且相同的字段可以保持不同類型的數據。
示例文檔
下面給出的示例顯示了一個博客網站,僅僅是一個逗號分隔的鍵值對的文檔結構。
{ _id: ObjectId(7df78ad8902c) title: 'MongoDB Overview', description: 'MongoDB is no sql database', by: 'yiibai tutorial', url: 'http://www.yiibai.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100, comments: [ { user:'user1', message: 'My first comment', dateCreated: new Date(2011,1,20,2,15), like: 0 }, { user:'user2', message: 'My second comments', dateCreated: new Date(2011,1,25,7,45), like: 5 } ] }
在Windows上安裝MongoDB
要在Windows上安裝MongoDB,首先從 http://www.mongodb.org/downloads 下載 MongoDB 的最新版本
現在,提取下載的文件到c:\ 驅動器或其他位置。 確保壓縮文件夾名稱是 mongodb-win32-i386-[version] 或 mongodb-win32-x86_64-[version]. 這裏 [version] 是MongoDB的下載版本。
現在,打開命令提示符並運行以下命令
C:\>move mongodb-win64-* mongodb 1 dir(s) moved. C:\>
如果提取 mondodb 在不同的位置,然後進入這個路徑通過命令 cd FOOLDER/DIR 現在運行上面給出的過程。
下面是簡單的安裝步驟,第一步:
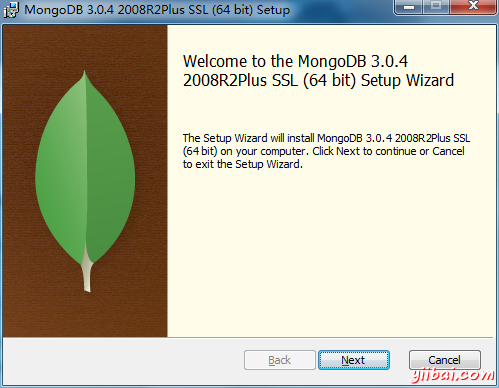
第二步:選擇自定安裝(可以自己定義安裝目錄)
第三步:選擇安裝目錄
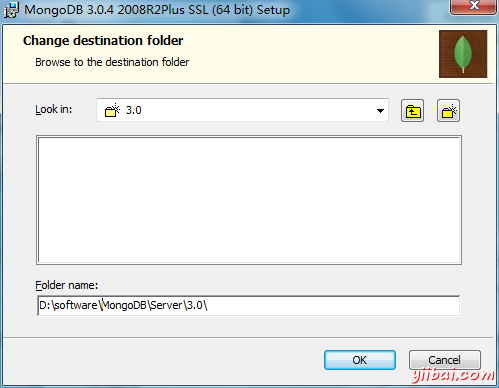
第四步:選擇安裝目錄
第五步:安裝完成!
如果安裝 MongoDB 在不同的位置(建議安裝到 D:\software),那麼需要設置路徑 dbpath 在 mongod.exe 指向 data 備用路徑。請看看下面的命令
在命令提示符下導航到bin目錄,當前到 MongoDB 的安裝文件夾。本教程中安裝文件夾是(爲了保持與本教程一致,建議也安裝到這個目錄,如果你喜歡折騰,那我攔也攔不住):D:\software
C:\Users\yiibai>d: D:\>cd "software" D:\software>cd MongoDB\Server\3.0\bin D:\software\MongoDB\Server\3.0\bin> mongod.exe --dbpath "d:\software\MongoDB\Server\3.0\data"
這將顯示在等待連接的控制檯輸出消息,指示 mongod.exe 成功運行過程。
現在運行的MongoDB,需要打開一個命令提示符,發出以下命令
D:\software\MongoDB\Server\3.0\bin>mongo.exe MongoDB shell version: 3.0.4 connecting to: test >db.test.save( { a: 1 } ) >db.test.find() { "_id" : ObjectId(5879b0f65a56a454), "a" : 1 } >
這將顯示已安裝的 MongoDB 併成功運行。下一次當您要運行 MongoDB 只需要發出命令:
D:\software\MongoDB\Server\3.0\bin>mongod.exe --dbpath "d:\software\MongoDB\Server\3.0\data" D:\software\MongoDB\Server\3.0\bin>mongo.exe
出現錯誤:
D:\software\MongoDB\Server\3.0\bin>mongod.exe --dbpath "d:\software\MongoDB\Server\3.0\data"
2015-07-11T08:47:22.896+0800 I CONTROL Hotfix KB2731284 or later update is not
installed, will zero-out data files
2015-07-11T08:47:22.896+0800 I STORAGE [initandlisten] exception in initAndList
en: 29 Data directory d:\software\MongoDB\Server\3.0\data not found., terminating
解決辦法:在d:\software\MongoDB\Server\3.0\目錄下創建一個新目錄:data
注:再新打開一個命令行窗口,用於執行 MongoDB 各種命令。
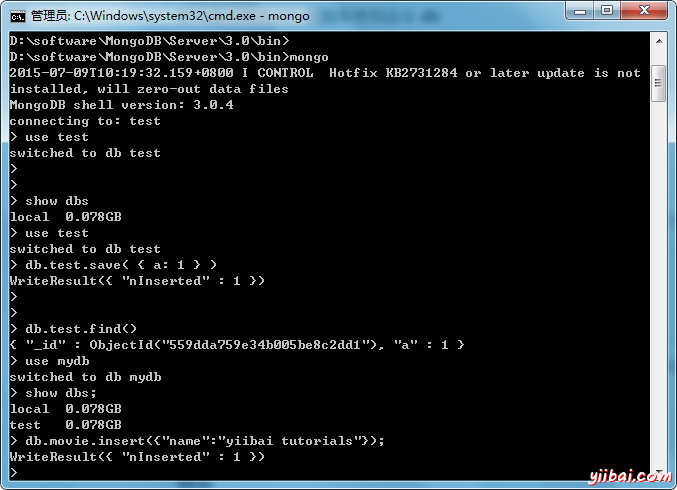
創建數據庫
MongoDB use DATABASE_NAME 用於創建數據庫。該命令如果數據庫不存在,將創建一個新的數據庫, 否則將返回現有的數據庫。
語法
use DATABASE語句的基本語法如下:
use DATABASE_NAME
例子:
如果想創建一個數據庫名稱爲
>use mydb
switched to db mydb
要檢查當前選擇的數據庫使用命令 db
>db
mydb
如果想查詢數據庫列表,那麼使用命令 show dbs.
>show dbs local 0.78125GB test 0.23012GB
所創建的數據庫(mydb)不存在於列表中。要顯示的數據庫,需要至少插入一個文檔進去。
>db.movie.insert({"name":"yiibai tutorials"}) >show dbs local 0.78125GB mydb 0.23012GB test 0.23012GB
MongoDB的默認數據庫是test。 如果沒有創建任何數據庫,那麼集合將被保存在測試數據庫。
刪除數據庫
MongoDB db.dropDatabase() 命令用於刪除現有的數據庫。
語法
dropDatabase()指令的基本語法如下:
db.dropDatabase()
這將刪除選定的數據庫。如果沒有選擇任何數據庫,那麼它會刪除默認的「test」數據庫
例子:
如果想刪除新的數據庫
>use mydb
switched to db mydb >db.dropDatabase() >{ "dropped" : "mydb", "ok" : 1 } >
創建集合
MongoDB 的 db.createCollection(name, options) 用於創建集合。 在命令中, name 是要創建集合的名稱。 Options 是一個文檔,用於指定集合的配置
參數
類型
描述
Name
String
要創建的集合的名稱
Options
Document
(可選)指定有關內存大小和索引選項
選項參數是可選的,所以需要指定集合的唯一名字。
語法
createCollection()方法的基本語法如下
>use test
switched to db test >db.createCollection("mycollection") { "ok" : 1 } >
可以通過使用 show collections 命令來檢查創建的集合
>show collections
mycollection
system.indexes
選項列表
字段
類型
描述
capped
Boolean
(可選)如果爲true,它啓用上限集合。上限集合是一個固定大小的集合,當它達到其最大尺寸會自動覆蓋最老的條目。 如果指定true,則還需要指定參數的大小。
autoIndexID
Boolean
(可選)如果爲true,自動創建索引_id字段。默認的值是 false.
size
number
(可選)指定的上限集合字節的最大尺寸。如果capped 是true,那麼還需要指定這個字段。
max
number
(可選)指定上限集合允許的最大文件數。
儘管插入文檔,MongoDB首先檢查字段集合的上限大小,那麼它會檢查最大字段。
語法 :
>db.createCollection("mycol", { capped : true, autoIndexID : true, size : 6142800, max : 10000 } ) { "ok" : 1 } >
在MongoDB中並不需要創建集合。 當插入一些文檔 MongoDB 會自動創建集合。
>db.yiibai.insert({"name" : "yiibai"}) >show collections
mycol
mycollection
system.indexes
yiibai >
刪除集合
MongoDB 的 db.collection.drop() 用於從數據庫中刪除集合。
語法
drop() 命令的基本語法如下
db.COLLECTION_NAME.drop()
例子:
下面給出的例子將刪除給定名稱的集合:mycollection
>use mydb
switched to db mydb >db.mycollection.drop() true >
插入文檔
將數據插入到MongoDB集合,需要使用MongoDB 的 insert() 方法。
語法
insert()命令的基本語法如下:
>db.COLLECTION_NAME.insert(document)
例子
>db.mycol.insert({ _id: ObjectId(7df78ad8902c), title: 'MongoDB Overview', description: 'MongoDB is no sql database', by: 'yiibai tutorials', url: 'http://www.yiibai.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 })
這裏 mycol 是我們的集合名稱,它是在之前的教程中創建。如果集合不存在於數據庫中,那麼MongoDB創建此集合,然後插入文檔進去。
在如果我們不指定_id參數插入的文檔,那麼 MongoDB 將爲文檔分配一個唯一的ObjectId。
_id 是12個字節十六進制數在一個集合的每個文檔是唯一的。 12個字節被劃分如下:
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id, 3 bytes incrementer)
要以單個查詢插入多個文檔,可以通過文檔 insert() 命令的數組方式。
例子
>db.post.insert([ { title: 'MongoDB Overview', description: 'MongoDB is no sql database', by: 'yiibai tutorials', url: 'http://www.yiibai.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }, { title: 'NoSQL Database', description: 'NoSQL database doesn't have tables',
by: 'yiibai tutorials',
url: 'http://www.yiibai.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 20, comments: [ { user:'user1', message: 'My first comment', dateCreated: new Date(2013,11,10,2,35), like: 0 } ] } ])
查詢文檔
要從集合查詢MongoDB數據,需要使用MongoDB的 find()方法。
語法
find()方法的基本語法如下
>db.COLLECTION_NAME.find()
find() 方法將在非結構化的方式顯示所有的文件。 如果顯示結果是格式化的,那麼可以用pretty() 方法。
語法
>db.mycol.find().pretty()
例子
>db.mycol.find().pretty() { "_id": ObjectId(7df78ad8902c), "title": "MongoDB Overview", "description": "MongoDB is no sql database", "by": "yiibai tutorials", "url": "http://www.yiibai.com", "tags": ["mongodb", "database", "NoSQL"], "likes": "100" } >
除了find()方法還有findOne()方法,僅返回一個文檔。
RDBMS Where子句等效於MongoDB
查詢文檔在一些條件的基礎上,可以使用下面的操作
操作
語法
示例
RDBMS等效語句
Equality
{
db.mycol.find({"by":"yiibai tutorials"}).pretty()
where by = 'yiibai tutorials'
Less Than
{
db.mycol.find({"likes":{$lt:50}}).pretty()
where likes < 50
Less Than Equals
{
db.mycol.find({"likes":{$lte:50}}).pretty()
where likes <= 50
Greater Than
{
db.mycol.find({"likes":{$gt:50}}).pretty()
where likes > 50
Greater Than Equals
{
db.mycol.find({"likes":{$gte:50}}).pretty()
where likes >= 50
Not Equals
{
db.mycol.find({"likes":{$ne:50}}).pretty()
where likes != 50
AND 在 MongoDB
語法
在 find()方法,如果您傳遞多個鍵通過","將它們分開,那麼MongoDB對待它就如AND條件一樣。基本語法如下所示:
>db.mycol.find({key1:value1, key2:value2}).pretty()
例子
下面給出的例子將顯示所有教程含「yiibai tutorials」和其標題是「MongoDB Overview」
>db.mycol.find({"by":"yiibai tutorials","title": "MongoDB Overview"}).pretty() { "_id": ObjectId(7df78ad8902c), "title": "MongoDB Overview", "description": "MongoDB is no sql database", "by": "yiibai tutorials", "url": "http://www.yiibai.com", "tags": ["mongodb", "database", "NoSQL"], "likes": "100" } >
對於上面給出的例子相當於where子句:' where by='yiibai tutorials' AND title='MongoDB Overview' '。可以傳遞任何數目的鍵-值對在find子句。
OR 在 MongoDB
語法
要查詢基於OR條件的文件,需要使用$or關鍵字。OR的基本語法如下所示:
>db.mycol.find( { $or: [ {key1: value1}, {key2:value2} ] } ).pretty()
例子
下面給出的例子將顯示所有撰寫含有 'yiibai tutorials' 或是標題爲 'MongoDB Overview' 的教程
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() { "_id": ObjectId(7df78ad8902c), "title": "MongoDB Overview", "description": "MongoDB is no sql database", "by": "yiibai tutorials", "url": "http://www.yiibai.com", "tags": ["mongodb", "database", "NoSQL"], "likes": "100" } >
使用 AND 和 OR 在一起
例子
下面給出的例子顯示有喜歡數大於100 的文檔,其標題要麼是 'MongoDB Overview' 或 'yiibai tutorials'. 等效於SQL的where子句:**'where likes>10 AND (by = 'yiibai tutorials' OR title = 'MongoDB Overview')'**
>db.mycol.find("likes": {$gt:10}, $or: [{"by": "yiibai tutorials"}, {"title": "MongoDB Overview"}] }).pretty() { "_id": ObjectId(7df78ad8902c), "title": "MongoDB Overview", "description": "MongoDB is no sql database", "by": "yiibai tutorials", "url": "http://www.yiibai.com", "tags": ["mongodb", "database", "NoSQL"], "likes": "100" } >
更新文檔
MongoDB的update()和save()方法用於更新文檔到一個集合。 update()方法將現有的文檔中的值更新,而save()方法使用傳遞到save()方法的文檔替換現有的文檔。
MongoDB Update() 方法
語法
update()方法的基本語法如下
>db.COLLECTION_NAME.update(SELECTIOIN_CRITERIA, UPDATED_DATA)
例子
考慮mycol集合有如下數據。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai Overview"}
下面的例子將設置其標題「MongoDB Overview」的文件爲新標題爲「New MongoDB Tutorial」
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}}) >db.mycol.find() { "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Tutorial Overview"} >
默認情況下,MongoDB將只更新單一文件,更新多,需要一個參數 'multi' 設置爲 true。
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}},{multi:true})
MongoDB Save() 方法
save() 方法取代,通過新文檔到 save()方法
語法
mongodb 的 save()方法如下所示的基本語法:
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})
例子
下面的例子將替換該文件_id '5983548781331adf45ec7'
>db.mycol.save( { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai New Topic", "by":"Yiibai Yiibai" } ) >db.mycol.find() { "_id" : ObjectId(5983548781331adf45ec5), "title":"Yiibai Yiibai New Topic", "by":"Yiibai Yiibai"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai Overview"} >
刪除文檔
MongoDB 的 **remove()**方法用於從集合中刪除文檔。remove()方法接受兩個參數。一個是標準缺失,第二是justOne標誌
deletion criteria : 根據文件(可選)刪除條件將被刪除。
justOne : (可選)如果設置爲true或1,然後取出只有一個文檔。
語法
**remove()**方法的基本語法如下
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)
例子
考慮mycol集合有如下數據。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai Overview"}
下面的例子將刪除所有的文件,其標題爲 'MongoDB Overview'
>db.mycol.remove({'title':'MongoDB Overview'}) >db.mycol.find() { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Toturials Overview"} >
只刪除一個
如果有多個記錄,並要刪除僅第一條記錄,然後在 remove()方法設置參數 justOne 。
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
刪除所有文件
如果沒有指定刪除條件,則MongoDB將從集合中刪除整個文件。這相當於SQL的 truncate 命令。
>db.mycol.remove() >db.mycol.find() >
MongoDB投影
mongodb投影意義是隻選擇需要的數據,而不是選擇整個一個文檔的數據。如果一個文檔有5個字段,只需要顯示3個,只從中選擇3個字段。
MongoDB的find()方法,解釋了MongoDB中查詢文檔接收的第二個可選的參數是要檢索的字段列表。在MongoDB中,當執行find()方法,那麼它會顯示一個文檔的所有字段。要限制這一點,需要設置字段列表值爲1或0。1是用來顯示字段,而0被用來隱藏字段。
語法
find()方法的基本語法如下
>db.COLLECTION_NAME.find({},{KEY:1})
例子
考慮集合 myycol 有下列數據
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai Overview"}
下面的例子將顯示文檔的標題,在查詢文檔時。
>db.mycol.find({},{"title":1,_id:0}) {"title":"MongoDB Overview"} {"title":"NoSQL Overview"} {"title":"Yiibai Yiibai Overview"} >
請注意在執行find()方法時_id字段始終顯示,如果不想要顯示這個字段,那麼需要將其設置爲0
限制文檔
MongoDB Limit() 方法
要在MongoDB中限制記錄,需要使用limit()方法。 limit() 方法接受一個數字類型的參數,這是要顯示的文檔數量。
語法
limit()方法的基本語法如下
>db.COLLECTION_NAME.find().limit(NUMBER)
例子
考慮集合 myycol 有下列數據
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai Overview"}
下面的例子將只顯示2個文檔,在查詢文檔時。
>db.mycol.find({},{"title":1,_id:0}).limit(2) {"title":"MongoDB Overview"} {"title":"NoSQL Overview"} >
如果不指定 **limit()**方法的參數數量,然後它會顯示集合中的所有文檔。
MongoDB Skip() 方法
除了 **limit()**方法還有一個方法 **skip()**也接受數字類型參數並用於跳過文件數。
語法
skip() 方法的基礎語法如下所示:
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
例子:
下面的例子將僅顯示第二個文檔。
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1) {"title":"NoSQL Overview"} >
請注意,skip() 方法的默認值是 0
文檔排序
要排序MongoDB中的文檔,需要使用 sort()方法。 sort() 方法接受一個包含字段列表以及排序順序的文檔。 要使用1和-1指定排序順序。1用於升序,而-1是用於降序。
語法
sort()方法的基本語法如下
>db.COLLECTION_NAME.find().sort({KEY:1})
例子
考慮集合 myycol 有如下數據
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"} { "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"} { "_id" : ObjectId(5983548781331adf45ec7), "title":"Yiibai Yiibai Overview"}
下面的例子將顯示的文件排序按標題降序排序。
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1}) {"title":"Yiibai Yiibai Overview"} {"title":"NoSQL Overview"} {"title":"MongoDB Overview"} >
請注意,如果不指定排序類型,那麼 sort() 方法將以升序排列文檔。
MongoDB索引
索引支持查詢高效率執行。如果沒有索引,MongoDB必須掃描集合中的每一個文檔,然後選擇那些符合查詢語句的文檔。若需要 mongod 來處理大量數據,掃描是非常低效的。
索引是特殊的數據結構,存儲在一個易於設置遍歷形式的數據的一小部分。索引存儲在索引中指定特定字段的值或一組字段,並排序字段的值。
要創建索引,需要使用MongoDB的ensureIndex()方法。
語法
ensureIndex()方法的基本語法如下
>db.COLLECTION_NAME.ensureIndex({KEY:1})
這裏鍵是要創建索引字段,1是按名稱升序排序。若以按降序創建索引,需要使用 -1.
例子
>db.mycol.ensureIndex({"title":1}) >
在 ensureIndex()方法,可以通過多個字段,來創建多個字段索引。
>db.mycol.ensureIndex({"title":1,"description":-1}) >
ensureIndex() 方法還接受選項列表(這是可選),其列表如下:
參數
類型
描述
background
Boolean
構建索引在後臺以便建立索引不阻止其它數據庫活動。指定true時建立在後臺。缺省值是false.
unique
Boolean
創建一個唯一的索引,以使集合將不接受插入的的文檔,其中的索引關鍵字或鍵匹配索引的現有值。指定true以創建唯一索引。缺省值是 false.
name
string
索引的名稱。如果未指定,MongoDB通過連接索引的字段和排序順序的名稱生成一個索引名。
dropDups
Boolean
創建一個字段唯一索引時可能會有重複。MongoDB索引鍵僅第一次出現,並從集合中刪除包含該鍵後續出現的所有文檔。指定true以創建唯一索引。缺省值是 false.
sparse
Boolean
如果爲true,索引只引用與指定的字段的文檔。這些索引使用更少的空間,但在某些情況下表現不同(特別是排序)。缺省值是 false.
expireAfterSeconds
integer
指定的值,以秒爲單位,作爲一個TTL控制MongoDB保留在此集合文件多久。
v
index version
索引版本號。默認的索引版本取決於mongod創建索引時運行的版本。
weights
document
重量(weight )是一個數字,它是從1至99,999的數字,表示字段相對於其它索引字段在得分方面的意義。
default_language
string
對於文本索引,併爲詞幹分析器和標記生成器列表中的語言決定了停用詞和規則。它的默認值: english.
language_override
string
對於一個文本索引,包含在文檔中指定字段的名稱,語言來覆蓋默認語言。它的默認值:language.
MongoDB 聚合
聚合操作處理數據記錄並返回計算結果。從多個文檔聚合分組操作數值,並可以執行多種對分組數據業務返回一個結果。 在SQL中的count(*),使用group by 與mongodb的聚合是等效的。 對於MongoDB的聚合,使用的是aggregate()方法。
語法
aggregate()方法的基本語法如下
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
例子:
在集合中有以下數據:
{ _id: ObjectId(7df78ad8902c) title: 'MongoDB Overview', description: 'MongoDB is no sql database', by_user: 'Yiibai Yiibai ',
url: 'http://www.yiibai.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }, { _id: ObjectId(7df78ad8902d) title: 'NoSQL Overview', description: 'No sql database is very fast', by_user: 'Yiibai Yiibai', url: 'http://www.yiibai.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 10 }, { _id: ObjectId(7df78ad8902e) title: 'Neo4j Overview', description: 'Neo4j is no sql database', by_user: 'Neo4j', url: 'http://www.neo4j.com', tags: ['neo4j', 'database', 'NoSQL'], likes: 750 },
現在從上面的集合,如果想知道每一個用戶編寫的教程是多少,那麼使用aggregate()方法,如下圖所示的列表:
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}]) { "result" : [ { "_id" : "Yiibai Yiibai", "num_tutorial" : 2 }, { "_id" : "Neo4j", "num_tutorial" : 1 } ], "ok" : 1 } >
用於上述用途將等效於sql查詢: select by_user, count(*) from mycol group by by_user
另外,在上述例子中,我們已經使用字段by_user進行分組並計算總和,也就是by_user 出現各個次數。一個列表中可用的聚集表達式。
表達式
描述
示例
$sum
從集合累加所有文檔中的定義值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
$avg
從集合中的所有文檔計算所有給定值的平均值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
$min
從集合中獲取的所有文件的最小的相應值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
$max
從集合中的所有文檔中的相應值中獲取最大值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])
$push
插入數組值到文檔中
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])
$addToSet
插入值所產生的數組到文檔中,但不會產生重複
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])
$first
從源文件獲取根據分組的頭文件。通常,這使得只能意會再加上一些以前應用「$sort」 -stage
db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
$last
從源文件獲取根據分組的最後文件。通常,這使得只能意會再加上一些以前應用 「$sort」-stage.
db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
MongoDB 複製
複製是同步在多個服務器上的數據過程。複製提供了冗餘和數據在不同的數據庫服務器上的多個副本提高數據的可用性,複製防止在單個服務器上丟失數據庫。 複製也可以從硬件故障和服務中斷中恢復。帶有數據的其他副本,可以選擇其中一個災難恢復,報告或備份。
爲什麼要複製?
- 爲了讓數據安全
- 數據的高(24*7)可用性
- 災難恢復
- 無停機維護(如備份,索引重建,壓縮)
- 讀取縮放(額外的副本來讀取)
- 副本集是透明的應用
MongoDB複製的工作原理
MongoDB通過使用副本集的複製來實現。副本集是一組承載同一個數據集的mongod實例。在副本的一個節點是接收所有的寫操作主節點。所有的實例,次級,應用操作從主以便它們具有相同的數據集。副本集只能有一個主節點。
- 副本集是一組兩個或更多個節點(通常至少3節點是必需的)。
- 在副本集一個節點是主節點和其餘的節點都是次要的。
- 所有的數據複製是從主到次節點。
- 在自動故障轉移或維護時,選建立了主要和一個新的主節點被選擇。
- 故障節點的恢復後,再次加入副本集,並可以作爲一個輔助節點。
mongodb複製的典型圖如下圖,其中客戶端應用程序總是與主節點和主節點交互,然後將數據複製到輔助節點。
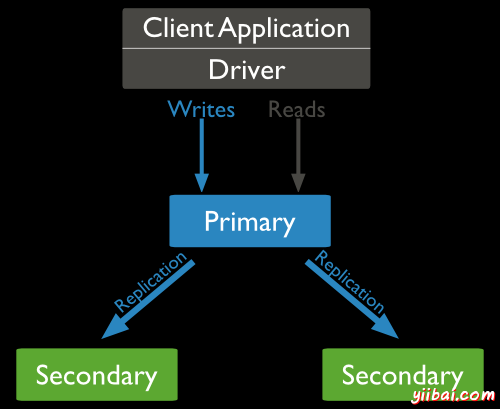
副本集特徵
- N個節點的集羣
- 任何節點可爲原發/主節點
- 所有的寫操作進入到主節點
- 自動故障轉移
- 自動恢復
- 協商一致選擇主節點
建立一個副本集
在本教程中,我們將獨立的 mongod 實例轉換爲副本集。 要轉換爲副本集,按照以下的步驟:
關閉已經運行的 MongoDB 服務器。
現在,通過指定--replSet選項啓動 MongoDB 服務器。--replSet 的基本語法如下:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
例子
mongod --port 27017 --dbpath "D:\software\MongoDB\Server\3.0\mongodb\data" --replSet rs0
這將啓動一個名爲rs0的一個mongod實例,端口爲: 27017
現在打開啓動命令提示符,然後連接到mongod實例
在Mongo的客戶端使用命令rs.initiate()來啓動一個新的副本集
要檢查副本設置配置,則使用命令rs.conf()
要檢查副本集發行的狀態,使用命令rs.status()
MongoDB創建備份
MongoDB數據轉儲
要使用 mongodump 命令來執行 MongoDB 數據庫備份。此命令將轉儲服務器的所有數據到轉儲目錄。有許多可用的選項,通過它可以限制數據量或創建遠程服務器備份。
語法
mongodump命令的基本語法如下
>mongodump
例子
啓動 mongod 服務器。假設 mongod 服務器運行在本地主機和端口 27017. 現在打開一個命令提示符,然後轉到你的MongoDB實例的bin目錄,然後輸入命令mongodump。
考慮mycol集合有以下數據。
>mongodump
該命令將連接到服務器127.0.0.1和端口27017,並備份所有數據到服務器上的目錄: /bin/dump/. 命令的輸出如下所示:
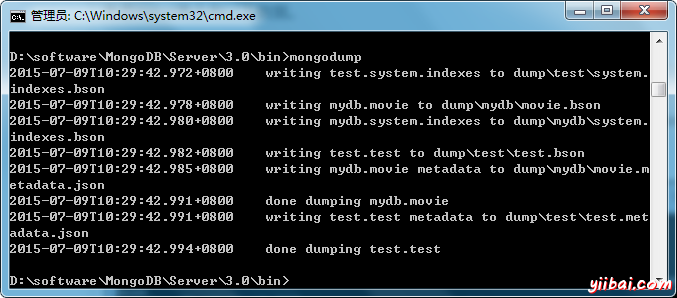
以上是可用的選項能夠與mongodump命令一起使用的列表。
此命令將只備份指定數據庫到指定的路徑
語法
描述
示例
mongodump --host HOST_NAME --port PORT_NUMBER
這個命令將備份指定的mongod實例的所有數據庫
mongodump --host yiibai.com --port 27017
mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY
mongodump --dbpath /data/db/ --out /data/backup/
mongodump --collection COLLECTION --db DB_NAME
此命令將僅備份指定的特定數據庫集合
mongodump --collection mycol --db test
數據恢復
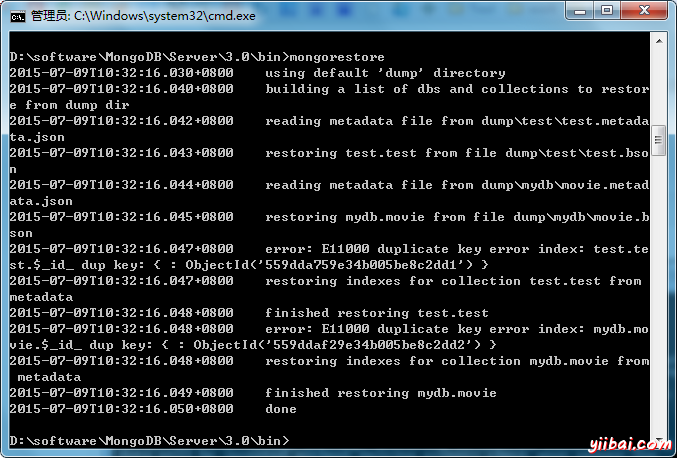
要恢復備份的MongoDB數據,則使用mongorestore命令。該命令將從備份目錄恢復所有的數據。
語法
mongorestore命令的基本語法
>mongorestore
這個命令的輸出如下所示: