水簡介
1. 概述
機器學習在現代軟體開發中至關重要。我們建立具有各種架構的模型,使用不同的演算法對其進行訓練,並透過使用神經網路改進我們的系統來實現令人難以置信的結果。
在本教程中,我們將探索h2o 平台。它幫助我們以簡單的方式創建、訓練和調整模型。
2.安裝開源h2o平台
我們可以從它的網站下載h2o。從目標資料夾中,我們可以啟動我們的 h2o 平台:
java -jar h2o.jar應用程式啟動後,我們可以透過http://localhost:54321存取 Web 控制台:
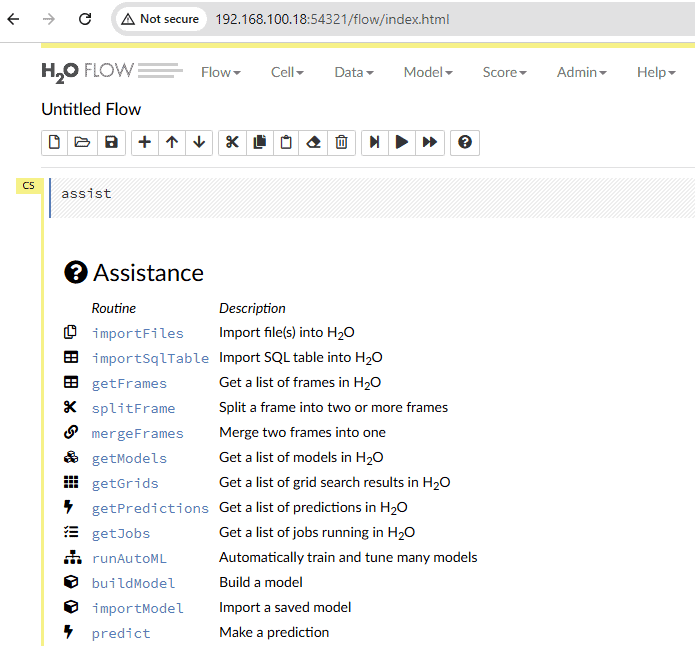
在主頁上,我們看到 H2O 平台中可用的操作清單。我們也可以使用功能表列顯示此清單。讓我們轉到頂部選單,然後選擇Help選項下的Assist Me 。
3. 準備資料集
在開始使用該平台之前,我們需要為模型訓練準備一個資料集。
我們將解決機器學習中的標準分類問題之一。此挑戰的流行資料集稱為iris.
在此資料集中,我們有不同類型的花朵及其屬性。我們以 CSV 格式下載它。在我們的資料集檔案中,我們應該看到以下資訊:
"sepal.length","sepal.width","petal.length","petal.width","variety"
5.1,3.5,1.4,.2,"Setosa"
4.9,3,1.4,.2,"Setosa"
4.7,3.2,1.3,.2,"Setosa"
...
5.8,2.7,3.9,1.2,"Versicolor"
6,2.7,5.1,1.6,"Versicolor"
5.4,3,4.5,1.5,"Versicolor"
...
6.5,3,5.2,2,"Virginica"
6.2,3.4,5.4,2.3,"Virginica"
5.9,3,5.1,1.8,"Virginica"這裡我們有鳶尾花的特徵以及與特定特徵組相匹配的花的名稱。
4. 訓練模型
讓我們使用準備好的資料集來訓練模型。
4.1.導入資料集
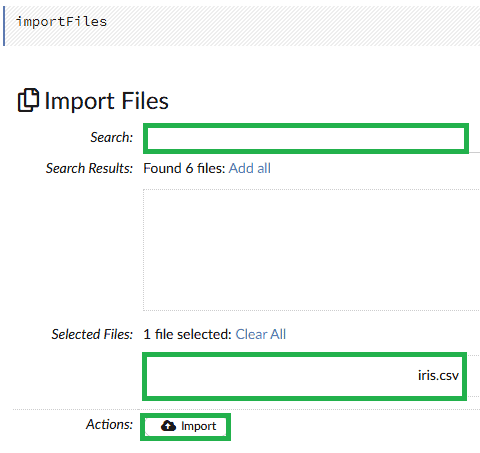
在 Web 控制台中,我們載入準備好的資料集。我們需要使用importFiles選項。在頂部選單中,選擇Data選項下的Import Files 。然後我們選擇包含資料集的資料夾,搜尋文件,然後按下Import按鈕:
4.2.準備訓練和測試資料集
資料集上傳後,我們可以使用getFrames函數。在頂部選單中,我們選擇Data選項下的List All Frames 。然後,我們按Parse按鈕:

在此操作的輸出中,我們可以看到資料集列描述和一些帶有範例的行。
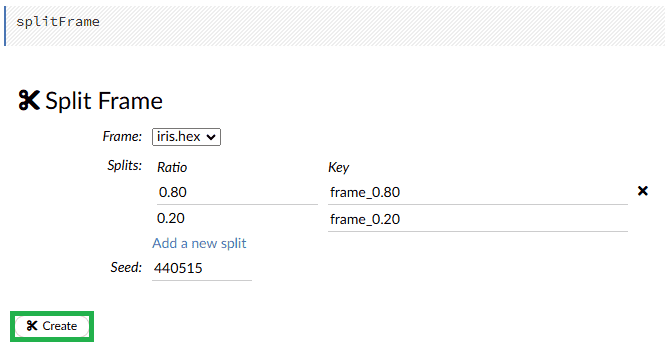
為了遵循標準機器學習實踐並為我們的模型準備數據,我們需要將數據集分為訓練和測試部分。我們將使用splitFrame函數.在頂部選單中,我們選擇Data選項下的Split Frame .現在,我們應用常見的 80/20 比率進行訓練和測試:
4.3.建構模型
現在,讓我們建立模型。在頂部選單中,我們選擇Model選項。我們將使用隨機森林演算法,該演算法非常適合分類問題:
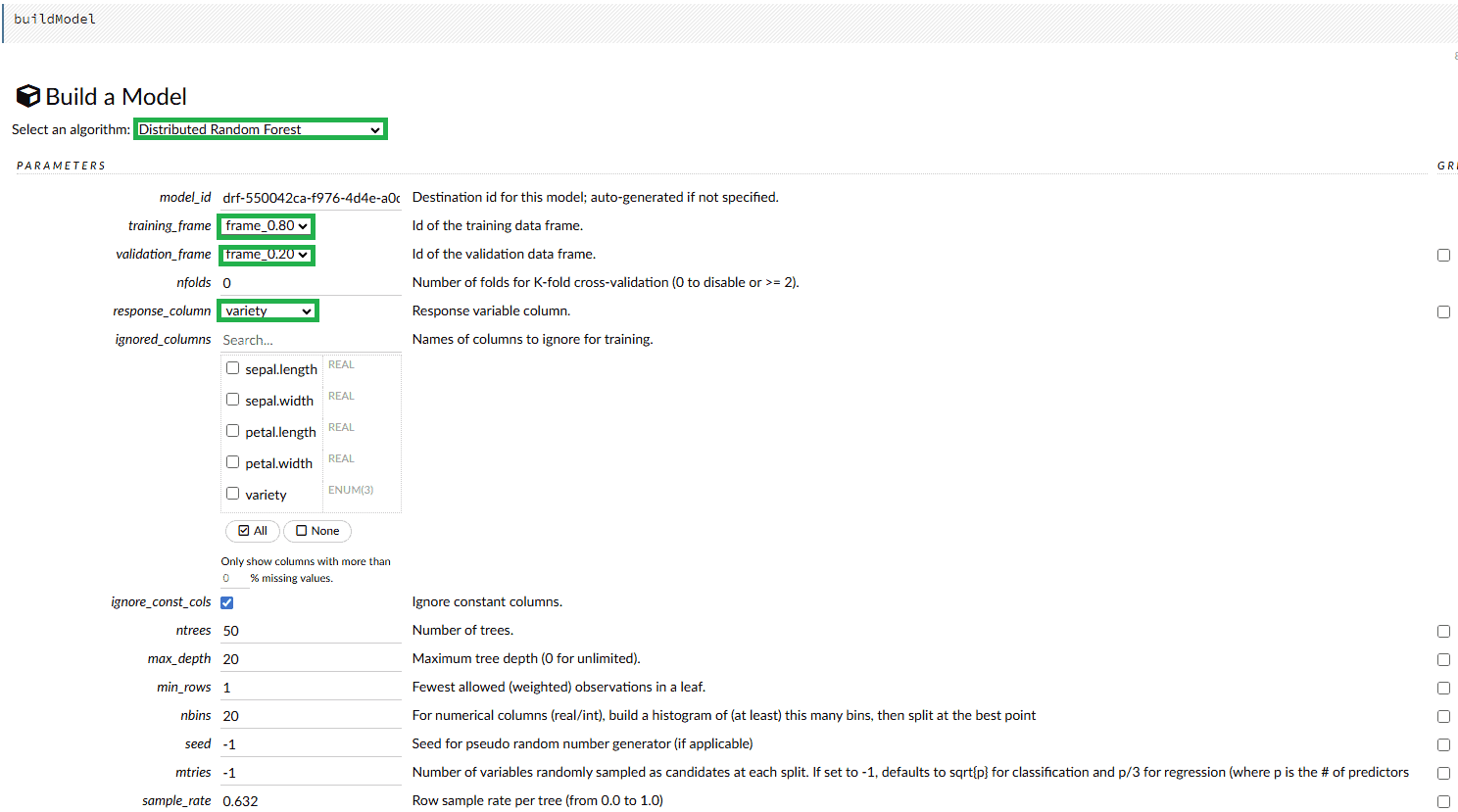
我們需要指定training_frame 、 validation_frame和response_column以使模型訓練過程成為可能。根據所選演算法,我們可以修改許多其他屬性以獲得更好的結果。配置完所有屬性後,我們按下Build Model按鈕:

4.4.自動機器學習功能
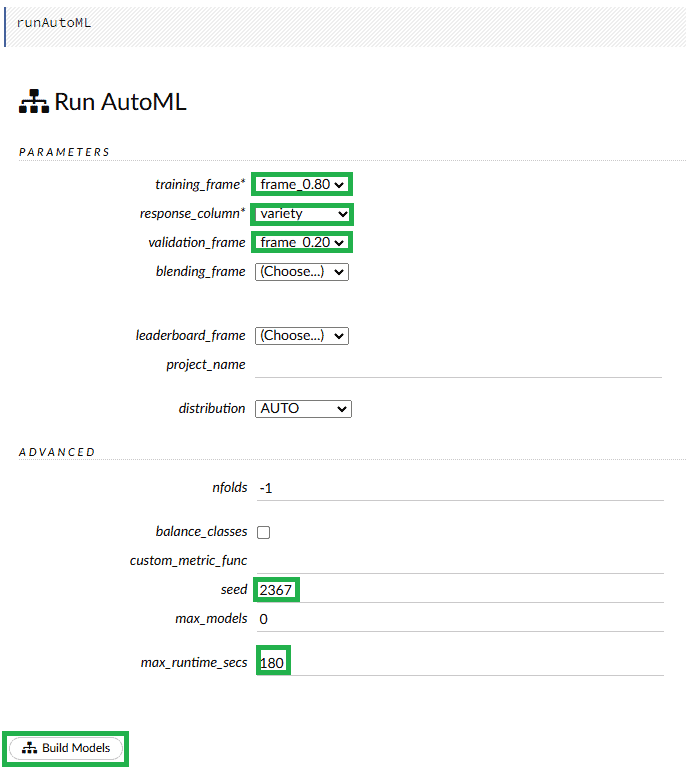
h2o 的另一個強大功能是 AutoML。在頂部選單中,我們選擇Model選項下的Run AutoML 。如果我們不知道具體要使用哪種演算法,我們可以選擇這個函數。這裡我們需要指定與一般建置過程中相同的參數。此外,我們設定了max_runtime_secs我們希望平台訓練所有模型。在此期間,AutoML 機制將訓練模型。我們設定的值越高,確定的最佳模型就越準確:
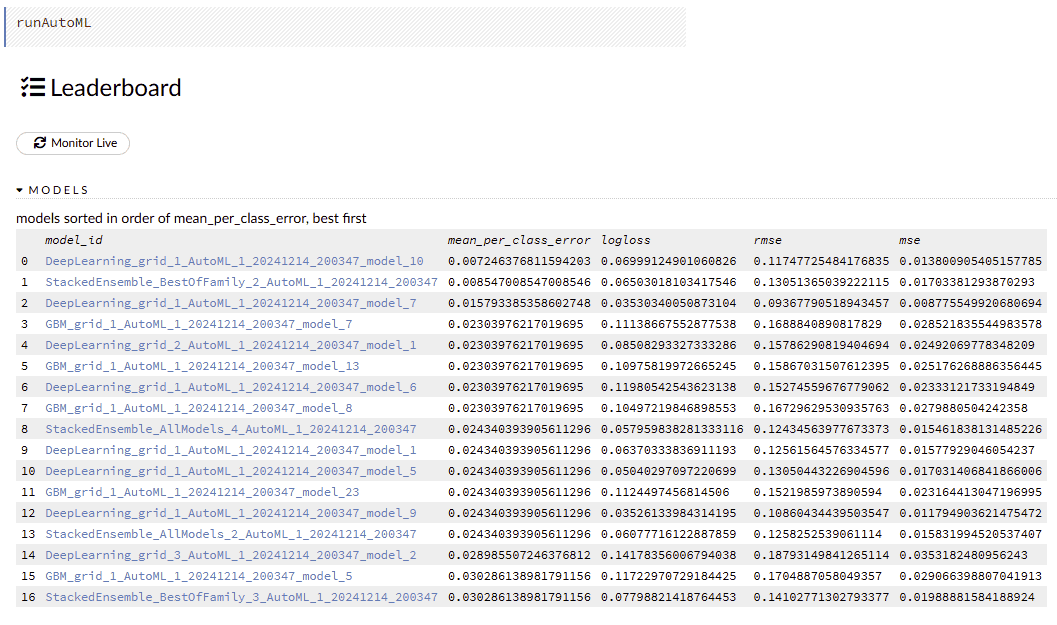
當我們完成模型訓練過程後,我們可以看到所有模型的排行榜。從這個清單中,我們可以選擇我們想要使用的合適的訓練模型:
4.5.下載模型
當我們建立模型時,我們可以下載必要的工件。 Download Gen Model按鈕讓我們可以下載包含 Java 應用程式所需類別的 JAR 存檔:

我們使用Download Model Deployment Package (MOJO)按鈕來下載模型本身:

5. 使用 Java 應用程式的模型預測
現在,讓我們在 Java 應用程式中使用我們的模型。
5.1.新增 h20 檔案
讓我們將從 h2o 控制台下載的檔案新增到應用程式專案內的libs資料夾中。現在,我們可以將其新增到類別路徑中。
5.2.依賴關係
讓我們新增模型相依性:
<dependency>
<groupId>ai.h2o</groupId>
<artifactId>h2o-genmodel</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/libs/h2o-genmodel.jar</systemPath>
</dependency>我們指定模型存檔的路徑。 groupId和artifactId在 h2o 中預先定義。
5.3.使用手動建立的模型進行預測
現在,讓我們看看如何在 Java 程式碼中使用我們的模型:
public class H2OModelLiveTest {
Logger logger = LoggerFactory.getLogger(H2OModelLiveTest.class);
@Test
public void givenH2OTrainedModel_whenPredictTheIrisByFeatures_thenExpectedFlowerShouldBeReturned() throws IOException, PredictException {
String mojoFilePath = "libs/mojo.zip";
MojoModel mojoModel = MojoModel.load(mojoFilePath);
EasyPredictModelWrapper model = new EasyPredictModelWrapper(mojoModel);
RowData row = new RowData();
row.put("sepal.length", 5.1);
row.put("sepal.width", 3.4);
row.put("petal.length", 4.6);
row.put("petal.width", 1.2);
MultinomialModelPrediction prediction = model.predictMultinomial(row);
Assertions.assertEquals("Versicolor", prediction.label);
logger.info("Class probabilities: ");
for (int i = 0; i < prediction.classProbabilities.length; i++) {
logger.info("Class " + i + ": " + prediction.classProbabilities[i]);
}
}
}我們從 MOJO 檔案建立一個MojoModel並用[EasyPredictModelWrapper](https://docs.h2o.ai/h2o/latest-stable/h2o-genmodel/javadoc/hex/genmodel/easy/EasyPredictModelWrapper.html)類別包裝它。接下來,我們準備一行包含要分類的花卉標準。然後,我們使用predictMultinomial()方法來取得預測。正如我們所看到的,這組屬性被分類為Versicolor 。此外,我們列印所有輸出參數。
輸出顯示我們的分類是準確的,機率為 0.9597,這對我們來說已經足夠了:
19:33:48.648 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class probabilities:
19:33:48.653 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class 0: 0.016846955011789237
19:33:48.653 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class 1: 0.9597659357519948
19:33:48.653 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class 2: 0.0233871092362160365.4.使用 AutoML 模型進行預測
現在,讓我們使用 AutoML h2o 函數提出的最佳模型來執行預測:
@Test
public void givenH2OTrainedAutoMLModel_whenPredictTheIrisByFeatures_thenExpectedFlowerShouldBeReturned() throws IOException, PredictException {
String mojoFilePath = "libs/automl_model.zip";
MojoModel mojoModel = MojoModel.load(mojoFilePath);
EasyPredictModelWrapper model = new EasyPredictModelWrapper(mojoModel);
RowData row = new RowData();
row.put("sepal.length", 5.1);
row.put("sepal.width", 3.4);introduction-to-
row.put("petal.length", 4.6);
row.put("petal.width", 1.2);
MultinomialModelPrediction prediction = model.predictMultinomial(row);
Assertions.assertEquals("Versicolor", prediction.label);
logger.info("Class probabilities: ");
for (int i = 0; i < prediction.classProbabilities.length; i++) {
logger.info("Class " + i + ": " + prediction.classProbabilities[i]);
}
}我們可以看到,該模型也成功完成了分類,結果相同。然而,在這種情況下,機率較低:
20:28:06.440 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class probabilities:
20:28:06.443 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class 0: 0.08536296008169375
20:28:06.443 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class 1: 0.8451806663486182
20:28:06.443 [main] INFO com.baeldung.h2o.H2OModelLiveTest - Class 2: 0.06945637356968806六、結論
在本文中,我們探索了 h2o 平台。使用這個工具,我們可以訓練神經網路並為 Java 應用程式準備工件。當我們想要避免深入主流的 ML 堆疊時,這很有幫助,因為這需要 Python 知識和其他函式庫。
與往常一樣,程式碼可以在 GitHub 上取得。