數據挖掘分類方法
在這裏,在這個教程中,我們將討論有關的其他分類方法,如遺傳算法,粗糙集方法和模糊集途徑。
遺傳算法
遺傳算法的思想是從自然進化而得。在遺傳算法首先初始種羣的建立。這個初始羣體包括隨機生成的規則。我們可以通過比特串代表的每個規則。
例如,假設在給定的訓練集的樣本由兩個布爾屬性,例如A1和A2中所述。而這個給定的訓練集包含兩個類,如C1和C2。
我們可以將規則編碼如果A1和A2不那麼C2爲位串100。在該位表示兩個最左邊的位所代表的屬性分別爲A1和A2。
同樣的規則IF NOT A1和A2的不那麼C1可以被編碼爲001。
注意:如果屬性的K值,其中K>2,那麼我們就可以使用K比特編碼的屬性值。類也編碼中相同的方式。
要記住的要點:
基於優勝劣汰的概念,一個新的人口構成爲包含在這些規則的當前人口和後代值優勝劣汰的規則也是如此。
該規則的適應度是通過一組訓練樣本的分類精度評估。
遺傳操作如交叉和變異應用到創建後代。
在交叉從對規則的子字符串是從一副新的規則交換到。
在突變,隨機選擇位在規則的字符串反轉。
粗糙集方法
發現內不精確和噪聲數據結構的關係,我們可以用粗糙集。
注意:這種方法只能在離散值屬性被應用。因此,連續屬性必須在使用前進行離散化。
粗糙集理論的基礎上,建立等價類的給定的訓練數據中。形成的等價類中的元組是不可分辨。這意味着樣品是相同的 wrt 來描述數據的屬性。
有一些班級在給定現實世界的數據,而不能在可用的屬性方面加以區分。我們可以用粗糙集大致定義這些類。
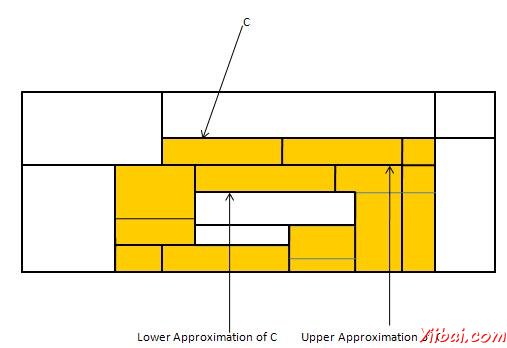
對於一個給定的類,C粗糙集的定義是由兩套近似如下:
C下近似 - C的下近似包括所有的數據元組,即對屬性的知識基礎。這些屬性一定會屬於C類。
C上近似 - C的上近似由所有基於屬性的知識的元組,不能被描述爲不屬於C。
下圖顯示了C類的上,下近似:
模糊集途徑
模糊集理論也被稱爲可能性理論。這個理論是由盧特菲扎德於1965年。這種方法是一種替代二值邏輯。這種理論使我們能夠在工作的抽象程度高;這個理論也爲我們提供手段來處理數據的不精確的測量。
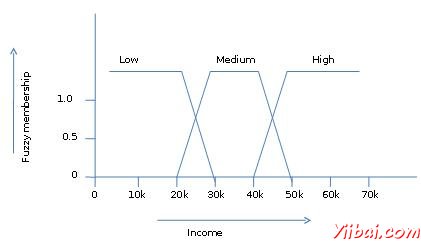
模糊集理論還允許處理模糊或不精確的事實。例如是一套高收入的成員是不準確的(例如,如果50,000元,高那麼約爲49,00048 000美元)。不像傳統的CRISP組,其中任一元素屬於S或它的補碼,但在模糊集理論中的元素可以屬於多於一個模糊集合。
例如,收入值49000美元同時屬於中,高模糊集,但程度有所不同。這個收入值模糊集符號如下:
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96
其中 m 爲隸屬函數,操作上分別模糊集medium_income 和 high_income。這個符號可以圖解顯示如下: