Pandas快速入門
這是一個Pandas快速入門教程,主要面向新用戶。這裏主要是爲那些喜歡「短平快」的讀者準備的,有興趣的讀者可通過其它教程文章來一步一步地更復雜的應用知識。
首先,假設您安裝好了Anaconda,現在啓動Anaconda開始學始本教程中的示例。工作界面如下所示 -
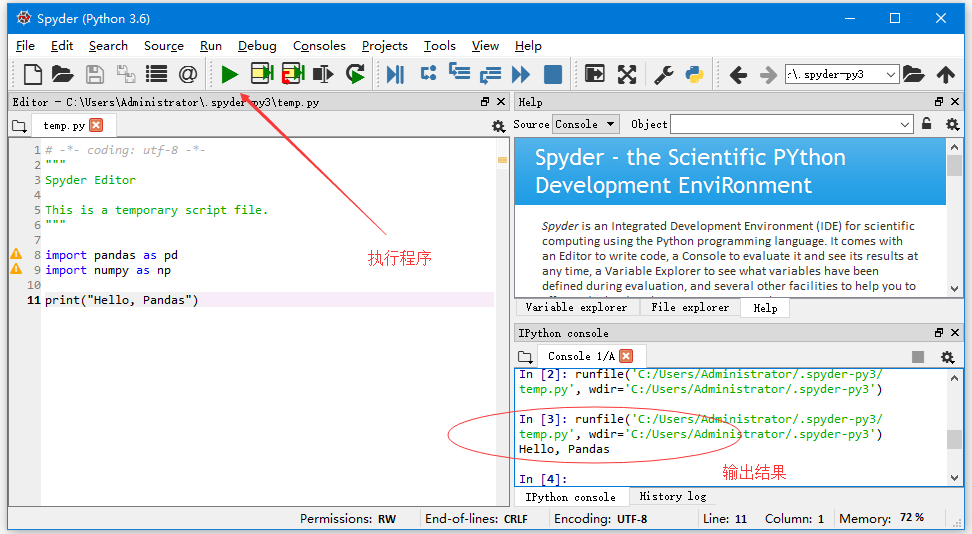
測試工作環境是否有安裝好了Pandas,導入相關包如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
print("Hello, Pandas")然後執行一下,看有沒有問題,如果正常應該會在終端輸出區看到以下結果 -
對象創建
通過傳遞值列表來創建一個系列,讓Pandas創建一個默認的整數索引:
import pandas as pd
import numpy as np
s = pd.Series([1,3,5,np.nan,6,8])
print(s)執行後輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64通過傳遞numpy數組,使用datetime索引和標記列來創建DataFrame:
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=7)
print(dates)
print("--"*16)
df = pd.DataFrame(np.random.randn(7,4), index=dates, columns=list('ABCD'))
print(df)執行後輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07'],
dtype='datetime64[ns]', freq='D')
--------------------------------
A B C D
2017-01-01 -0.732038 0.329773 -0.156383 0.270800
2017-01-02 0.750144 0.722037 -0.849848 -1.105319
2017-01-03 -0.786664 -0.204211 1.246395 0.292975
2017-01-04 -1.108991 2.228375 0.079700 -1.738507
2017-01-05 0.348526 -0.960212 0.190978 -2.223966
2017-01-06 -0.579689 -1.355910 0.095982 1.233833
2017-01-07 1.086872 0.664982 0.377787 1.012772通過傳遞可以轉換爲類似系列的對象的字典來創建DataFrame。參考以下示例代碼 -
import pandas as pd
import numpy as np
df2 = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20170102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
print(df2)執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A B C D E F
0 1.0 2017-01-02 1.0 3 test foo
1 1.0 2017-01-02 1.0 3 train foo
2 1.0 2017-01-02 1.0 3 test foo
3 1.0 2017-01-02 1.0 3 train foo有指定dtypes,參考以下示例代碼 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object如果使用IPython,則會自動啓用列名(以及公共屬性)的選項完成。 以下是將要完成的屬性的一個子集:
In [13]: df2.<TAB>
df2.A df2.bool
df2.abs df2.boxplot
df2.add df2.C
df2.add_prefix df2.clip
df2.add_suffix df2.clip_lower
df2.align df2.clip_upper
df2.all df2.columns
df2.any df2.combine
df2.append df2.combine_first
df2.apply df2.compound
df2.applymap df2.consolidate
df2.D可以看到,列A,B,C和D自動標籤完成。E也在一樣。其餘的屬性爲了簡潔而被截短。
查看數據
查看框架的頂部和底部的數據行。參考以下示例代碼 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=7)
df = pd.DataFrame(np.random.randn(7,4), index=dates, columns=list('ABCD'))
print(df.head())
print("--------------" * 10)
print(df.tail(3))執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A B C D
2017-01-01 -0.520856 -0.555019 -2.286424 1.745681
2017-01-02 1.114030 0.861933 0.795958 0.420670
2017-01-03 -0.343605 -0.937356 0.052693 -0.540735
2017-01-04 1.587684 -0.743756 0.021738 -0.702190
2017-01-05 1.243403 0.930299 0.234343 1.604182
------------------------------------------------------------
A B C D
2017-01-05 1.243403 0.930299 0.234343 1.604182
2017-01-06 -0.087004 -0.368055 1.434022 0.464193
2017-01-07 -1.248981 0.973724 -0.288384 -0.577388顯示索引,列和底層numpy數據,參考以下代碼 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=7)
df = pd.DataFrame(np.random.randn(7,4), index=dates, columns=list('ABCD'))
print("index is :" )
print(df.index)
print("columns is :" )
print(df.columns)
print("values is :" )
print(df.values)執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
index is :
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07'],
dtype='datetime64[ns]', freq='D')
columns is :
Index(['A', 'B', 'C', 'D'], dtype='object')
values is :
[[ 2.23820398 0.18440123 0.08039084 -0.27751926]
[-0.12335513 0.36641304 -0.28617579 0.34383109]
[-0.85403491 0.63876989 1.26032173 -1.27382333]
[-0.07262661 -0.01788962 0.28748668 1.12715561]
[-1.14293392 -0.88263364 0.72250762 -1.64051326]
[ 0.41864083 0.40545953 -0.14591541 -0.57168728]
[ 1.01383531 -0.22793823 -0.44045634 1.04799829]]描述顯示數據的快速統計摘要,參考以下示例代碼 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=7)
df = pd.DataFrame(np.random.randn(7,4), index=dates, columns=list('ABCD'))
print(df.describe())執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A B C D
count 7.000000 7.000000 7.000000 7.000000
mean -0.675425 -0.257835 0.144049 0.275621
std 1.697957 0.793953 1.301520 1.412291
min -2.595040 -1.200401 -1.230538 -0.976166
25% -1.992393 -0.723464 -0.897041 -0.800919
50% -1.050666 -0.445612 0.004719 -0.705840
75% 0.592677 0.068574 0.874195 1.398337
max 1.717166 1.150948 2.279856 2.416514調換數據,參考以下示例代碼 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.T)執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
2017-01-01 2017-01-02 2017-01-03 2017-01-04 2017-01-05 2017-01-06
A 0.932454 -2.148503 1.398975 1.565676 -0.167527 -0.242041
B 0.584585 1.373330 -0.069801 -0.102857 1.286432 -0.703491
C -0.345119 -0.680955 1.686750 1.184996 0.016170 -0.663963
D 0.431751 0.444830 -1.524739 0.040007 0.220172 1.423627通過軸排序,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.sort_index(axis=1, ascending=False))
`執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
D C B A
2017-01-01 0.426359 2.542352 -0.324047 0.418973
2017-01-02 -0.834625 -1.356709 0.150744 -1.690500
2017-01-03 -0.018274 0.900801 1.072851 0.149830
2017-01-04 -1.075027 -0.889379 -0.663223 -1.404002
2017-01-05 -1.273966 -1.335761 -1.356561 -1.135199
2017-01-06 -1.590793 0.693430 -0.504164 0.143386按值排序,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.sort_values(by='B'))
`執行上面示例代碼後,輸出結果如下 -
A B C D
2017-01-06 0.764517 -1.526019 0.400456 -0.182082
2017-01-05 -0.177845 -1.269836 -0.534676 0.796666
2017-01-04 -0.981485 -0.082572 -1.272123 0.508929
2017-01-02 -0.290117 0.053005 -0.295628 -0.346965
2017-01-03 0.941131 0.799280 2.054011 -0.684088
2017-01-01 0.597788 0.892008 0.903053 -0.821024選擇區塊
注意雖然用於選擇和設置的標準Python/Numpy表達式是直觀的,可用於交互式工作,但對於生產代碼,但建議使用優化的Pandas數據訪問方法
.at,.iat,.loc,.iloc和.ix。
獲取
選擇一列,產生一個系列,相當於df.A,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df['A'])
`執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
2017-01-01 0.317460
2017-01-02 -0.933726
2017-01-03 0.167860
2017-01-04 0.816184
2017-01-05 -0.745503
2017-01-06 0.505319
Freq: D, Name: A, dtype: float64選擇通過[]操作符,選擇切片行。參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df[0:3])
print("========= 指定選擇日期 ========")
print(df['20170102':'20170103'])
`執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A B C D
2017-01-01 1.103449 0.926571 -1.649978 -0.309270
2017-01-02 0.516404 -0.734076 -0.081163 -0.528497
2017-01-03 0.240356 0.231224 -1.463315 -1.157256
========= 指定選擇日期 ========
A B C D
2017-01-02 0.516404 -0.734076 -0.081163 -0.528497
2017-01-03 0.240356 0.231224 -1.463315 -1.157256按標籤選擇
使用標籤獲取橫截面,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.loc[dates[0]])
`執行上面示例代碼後,輸出結果如下 -
runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3')
A -0.483292
B -0.536987
C -0.889947
D 1.250857
Name: 2017-01-01 00:00:00, dtype: float64通過標籤選擇多軸,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.loc[:,['A','B']])
`執行上面示例代碼後,輸出結果如下 -
A B
2017-01-01 0.479048 -0.105106
2017-01-02 0.172920 0.086570
2017-01-03 -1.302485 -0.593550
2017-01-04 -0.595438 1.304054
2017-01-05 0.154267 1.336219
2017-01-06 -0.341204 0.781300顯示標籤切片,包括兩個端點,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.loc['20170102':'20170104',['A','B']])
`執行上面示例代碼後,輸出結果如下 -
A B
2017-01-02 1.062995 -0.108277
2017-01-03 1.962106 -0.294664
2017-01-04 -0.128576 0.717738減少返回對象的尺寸(大小),參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.loc['20170102',['A','B']])
`執行上面示例代碼後,輸出結果如下 -
A 0.252749
B 0.119747
Name: 2017-01-02 00:00:00, dtype: float64獲得標量值,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.loc[dates[0],'A'])
`執行上面示例代碼後,輸出結果如下 -
-0.0839903627822快速訪問標量(等同於先前的方法),參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.at[dates[0],'A'])
`執行上面示例代碼後,輸出結果如下 -
-0.0839903627822通過位置選擇
通過傳遞的整數的位置選擇,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iloc[3])
`執行上面示例代碼後,輸出結果如下 -
A 0.944506
B 1.035781
C 0.421373
D 0.017660
Name: 2017-01-04 00:00:00, dtype: float64通過整數切片,類似於numpy/python,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iloc[3:5,0:2])
`執行上面示例代碼後,輸出結果如下 -
A B
2017-01-04 -1.617068 0.548090
2017-01-05 -0.864247 0.419743通過整數位置的列表,類似於numpy/python樣式,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iloc[[1,2,4],[0,2]])
`執行上面示例代碼後,輸出結果如下 -
A C
2017-01-02 0.085091 0.568128
2017-01-03 0.729076 -0.451151
2017-01-05 -1.281975 -0.190119明確切片行,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iloc[1:3,:])
`執行上面示例代碼後,輸出結果如下 -
A B C D
2017-01-02 -1.123970 -0.010969 -1.076657 -0.538908
2017-01-03 -0.314408 0.004415 -0.356924 0.337539明確切片列,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iloc[:,1:3])
`執行上面示例代碼後,輸出結果如下 -
B C
2017-01-01 0.323663 1.027599
2017-01-02 -0.176624 -0.959683
2017-01-03 0.689698 0.622540
2017-01-04 1.864511 1.023157
2017-01-05 0.964123 2.062503
2017-01-06 -0.375143 0.231328要明確獲取值,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iloc[1,1])
`執行上面示例代碼後,輸出結果如下 -
0.829950900219要快速訪問標量(等同於先前的方法),參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df.iat[1,1])
`執行上面示例代碼後,輸出結果如下 -
-0.170996002652布爾索引
使用單列的值來選擇數據,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df[df.A > 0])
`執行上面示例代碼後,輸出結果如下 -
A B C D
2017-01-03 0.276486 -1.003779 0.721863 -0.558061
2017-01-04 1.177206 -0.464778 -0.116442 -0.385712
2017-01-06 0.846665 -1.398207 -0.145356 0.924342從滿足布爾條件的DataFrame中選擇值。,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df[df > 0])
`執行上面示例代碼後,輸出結果如下 -
A B C D
2017-01-01 NaN 1.963213 0.643244 0.945643
2017-01-02 0.364237 0.917368 NaN NaN
2017-01-03 0.702624 NaN 0.088565 NaN
2017-01-04 1.274313 NaN 2.313910 NaN
2017-01-05 2.586315 0.588273 NaN 1.482597
2017-01-06 NaN 0.405928 0.309201 NaN使用isin()方法進行過濾,參考以下示例程序 -
import pandas as pd
import numpy as np
dates = pd.date_range('20170101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
df2 = df.copy()
df2['E'] = ['one', 'one','two','three','four','three']
print(df2)
print("============= start to filter =============== ")
print(df2[df2['E'].isin(['two','four'])])
`執行上面示例代碼後,輸出結果如下 -
A B C D E
2017-01-01 0.723399 -0.369247 0.863941 -1.910875 one
2017-01-02 -0.047573 -0.609780 2.130650 -0.019281 one
2017-01-03 -0.566122 -0.850374 -0.031516 0.362023 two
2017-01-04 0.903819 -0.513673 0.118850 -0.351811 three
2017-01-05 -0.485232 -0.864457 1.396835 -1.696083 four
2017-01-06 0.272145 -0.644449 -1.319063 -0.201354 three
============= start to filter ===============
A B C D E
2017-01-03 -0.566122 -0.850374 -0.031516 0.362023 two
2017-01-05 -0.485232 -0.864457 1.396835 -1.696083 four