Spark架構
Spark遵循主從架構。它的集羣由一個主服務器和多個從服務器組成。
Spark架構依賴於兩個抽象:
- 彈性分佈式數據集(RDD)
- 有向無環圖(DAG)
彈性分佈式數據集(RDD)
彈性分佈式數據集是可以存儲在工作節點上的內存中的數據項組。
- 彈性:失敗時恢復數據。
- 分佈式:數據分佈在不同的節點之間。
- 數據集:數據組。
稍後將詳細瞭解RDD。
有向無環圖(DAG)
有向無環圖是一種有限的直接圖,它對數據執行一系列計算。每個節點都是RDD分區,邊緣是數據頂部的轉換。
下面來了解Spark架構。
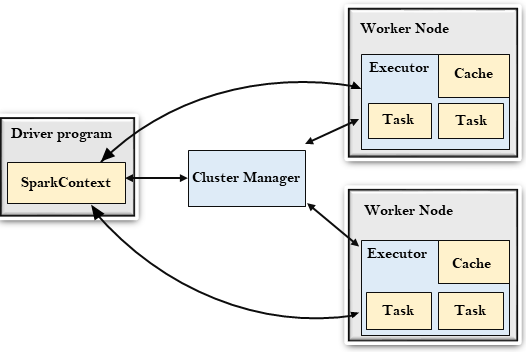
驅動程序
驅動程序是一個運行應用程序,由main()函數並創建SparkContext對象的進程。SparkContext的目的是協調spark應用程序,作爲集羣上的獨立進程集運行。
要在羣集上運行,SparkContext將連接到不同類型的羣集管理器,然後執行以下任務:
- 它在集羣中的節點上獲取執行程序。
- 它將應用程序代碼發送給執行程序。這裏,應用程序代碼可以通過傳遞給
SparkContext的JAR或Python文件來定義。 - 最後,
SparkContext將任務發送給執行程序以運行。
集羣管理器
集羣管理器的作用是跨應用程序分配資源。Spark能夠在大量集羣上運行。
它由各種類型的集羣管理器組成,例如:Hadoop YARN,Apache Mesos和Standalone Scheduler。
這裏,獨立調度程序是一個獨立的Spark集羣管理器,便於在一組空機器上安裝Spark。
工作節點
- 工作節點是從節點
- 它的作用是在集羣中運行應用程序代碼。
執行程序
- 執行程序是爲工作節點上的應用程序啓動的進程。
- 它運行任務並將數據保存在內存或磁盤存儲中。
- 它將數據讀寫到外部源。
- 每個應用程序都包含其執行者。
任務
- 任務被髮送給一個執行程序的工作單位。