Spark reduceByKey函數
在Spark中,reduceByKey函數是一種常用的轉換操作,它執行數據聚合。它接收鍵值對(K,V)作爲輸入,基於鍵聚合值並生成(K,V)對的數據集作爲輸出。
reduceByKey函數的示例
在此示例中,我們基於鍵聚合值。要在Scala模式下打開Spark,請按照以下命令操作。
$ spark-shell
使用並行化集合創建RDD。
scala> val data = sc.parallelize(Array(("C",3),("A",1),("B",4),("A",2),("B",5)))現在,可以使用以下命令讀取生成的結果。
scala> data.collect

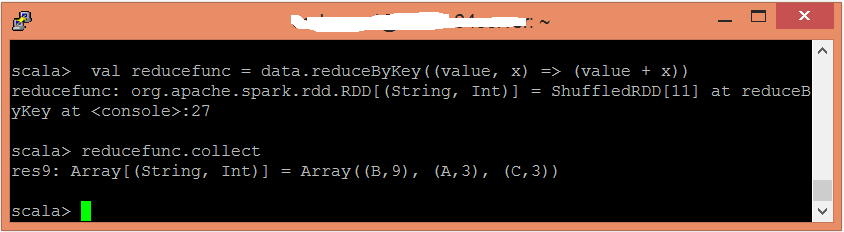
應用reduceByKey()函數來聚合值。
scala> val reducefunc = data.reduceByKey((value, x) => (value + x))現在,可以使用以下命令讀取生成的結果。
scala> reducefunc.collect