R語言正態分佈
在隨機收集來自獨立來源的數據中,通常觀察到數據的分佈是正常的。 這意味着,在繪製水平軸上的變量的值和垂直軸中的值的計數時,我們得到一個鐘形曲線。 曲線的中心代表數據集的平均值。 在圖中,百分之五十的值位於平均值的左側,另外五十分之一位於圖的右側。 統稱爲正態分佈。
R有四個內置函數來生成正態分佈。它們在下面描述 -
dnorm(x, mean, sd)
pnorm(x, mean, sd)
qnorm(p, mean, sd)
rnorm(n, mean, sd)以下是上述函數中使用的參數的描述 -
- x - 是數字的向量。
- p - 是概率向量。
- n - 是觀察次數(樣本量)。
- mean - 是樣本數據的平均值,默認值爲零。
- sd - 是標準偏差,默認值爲
1。
1.dnorm()函數
該函數給出給定平均值和標準偏差在每個點的概率分佈的高度。
setwd("F:/worksp/R")
# Create a sequence of numbers between -10 and 10 incrementing by 0.1.
x <- seq(-10, 10, by = .1)
# Choose the mean as 2.5 and standard deviation as 0.5.
y <- dnorm(x, mean = 2.5, sd = 0.5)
# Give the chart file a name.
png(file = "dnorm.png")
plot(x,y)
# Save the file.
dev.off()當我們執行上述代碼時,會產生以下結果 -
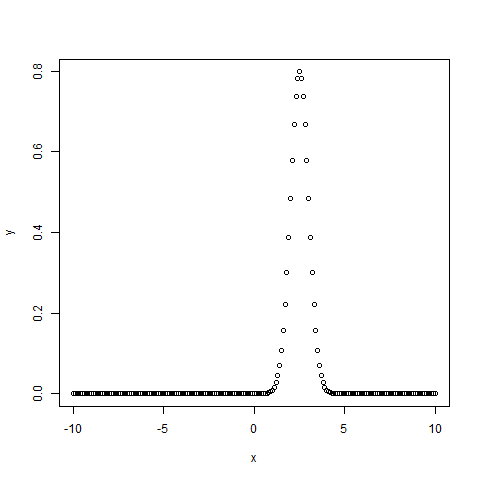
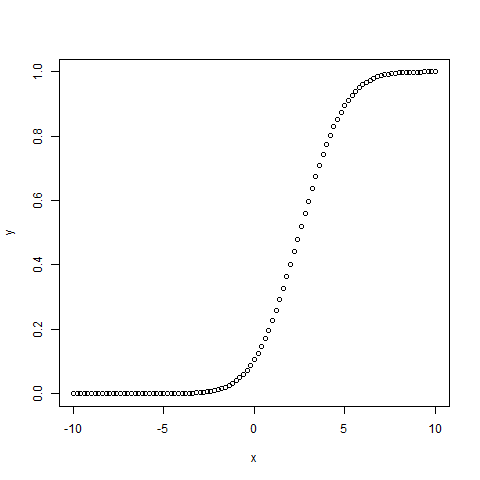
2.pnorm()函數
該函數給出正態分佈隨機數小於給定數值的概率。它也被稱爲「累積分佈函數」。
setwd("F:/worksp/R")
# Create a sequence of numbers between -10 and 10 incrementing by 0.2.
x <- seq(-10,10,by = .2)
# Choose the mean as 2.5 and standard deviation as 2.
y <- pnorm(x, mean = 2.5, sd = 2)
# Give the chart file a name.
png(file = "pnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()當我們執行上述代碼時,會產生以下結果 -
3.qnorm()函數
該函數採用概率值,並給出其累積值與概率值匹配的數字值。
setwd("F:/worksp/R")
# Create a sequence of probability values incrementing by 0.02.
x <- seq(0, 1, by = 0.02)
# Choose the mean as 2 and standard deviation as 3.
y <- qnorm(x, mean = 2, sd = 1)
# Give the chart file a name.
png(file = "qnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()當我們執行上述代碼時,會產生以下結果 -
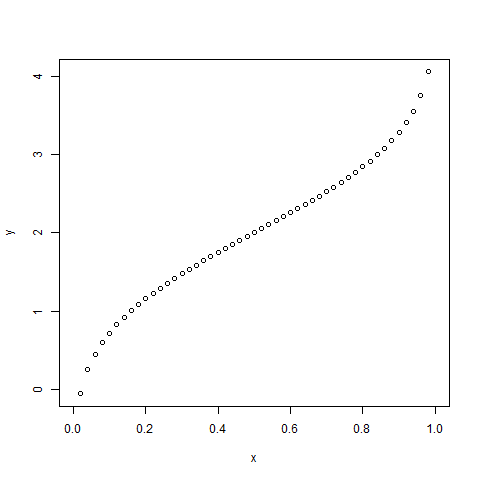
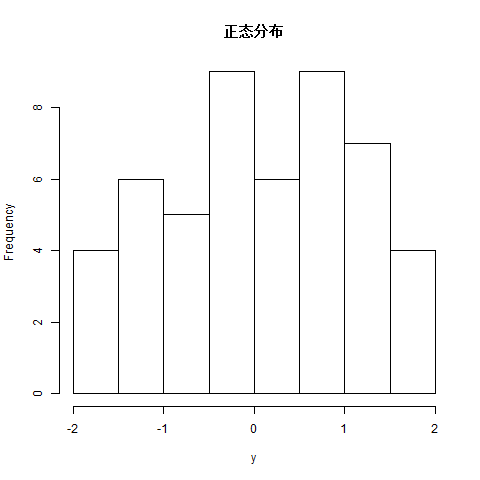
4.rnorm()函數
該函數用於生成分佈正常的隨機數,它將樣本大小作爲輸入,並生成許多隨機數。我們繪製直方圖以顯示生成數字的分佈。
setwd("F:/worksp/R")
# Create a sample of 50 numbers which are normally distributed.
y <- rnorm(50)
# Give the chart file a name.
png(file = "rnorm.png")
# Plot the histogram for this sample.
hist(y, main = "正態分佈")
# Save the file.
dev.off()當我們執行上述代碼時,會產生以下結果 -