NLTK包
在本章中,我們將學習如何開始使用自然語言工具包(軟件包)。
前提條件
如果想用自然語言處理來構建應用程序,那麼上下文中的變化就會使其變得非常困難。 語境因素影響機器如何理解特定句子。 因此,我們需要通過使用機器學習方法來開發自然語言應用程序,以便機器也能夠理解人類可以理解上下文的方式。
要構建這樣的應用程序,我們將使用名爲NLTK(自然語言工具包包)的Python包。
導入NLTK
在使用之前需要安裝NLTK,它可以在以下命令來安裝 -
pip install nltk要爲NLTK構建conda包,請使用以下命令 -
conda install -c anaconda nltk現在安裝NLTK包後,需要通過python命令提示符導入。通過在Python命令提示符下編寫以下命令來導入它 -
>>> import nltk下載NLTK的數據
現在導入NLTK後,我們還需要下載所需的數據。 它可以在Python命令提示符下通過以下命令完成 -
>>> nltk.download()安裝其他必需的軟件包
爲了使用NLTK構建自然語言處理應用程序,需要安裝必要的軟件包。如下 -
gensim
它是一個強大的語義建模庫,對許多應用程序很有用。可以通過執行以下命令來安裝它 -
pip install gensimpattern
它用於使gensim包正常工作。可以通過執行以下命令來安裝它 -
pip install pattern標記化,詞幹化和詞形化的概念
在本節中,我們將瞭解什麼是標記化,詞幹化和詞形化。
1. 標記化
它可以被定義爲將給定文本即字符序列分成稱爲令牌的較小單元的過程。令牌可以是單詞,數字或標點符號。 它也被稱爲分詞。 以下是標記化的一個簡單示例 -
輸入 - 芒果,香蕉,菠蘿和蘋果都是水果。
輸出 -

打斷給定文本的過程可以通過查找單詞邊界來完成。 單詞的結尾和新單詞的開頭稱爲單詞邊界。 文字的書寫體系和印刷結構會影響邊界。
在Python NLTK模塊中,有與標記化有關的不同包,可以根據需要將文本劃分爲標記。 一些軟件包如下所示 -
sent_tokenize包
顧名思義,這個軟件包會將輸入文本分成幾個句子。 可以使用下面的Python代碼導入這個包 -
from nltk.tokenize import sent_tokenizeword_tokenize包
這個包將輸入文本分成單詞。可以使用下面的Python代碼來導入這個包 -
from nltk.tokenize import word_tokenizeWordPuncttokenizer包
這個包將輸入文本分成單詞和標點符號。可以使用下面的Python代碼來導入這個包 -
from nltk.tokenize import WordPuncttokenizer2. 詞幹
在處理文字時,由於語法原因,我們遇到了很多變化。 這裏的變化的概念意味着必須處理像:democracy, democratic 和 democratization 等不同形式的相同詞彙。機器非常需要理解這些不同的單詞具有相同的基本形式。 通過這種方式,在分析文本的同時提取單詞的基本形式將會很有用。
我們可以通過阻止來實現這一點。 通過這種方式,可以說干擾是通過切斷單詞的結尾來提取單詞基本形式的啓發式過程。
在Python NLTK模塊中,有一些與stemming相關的其它包。 這些包可以用來獲取單詞的基本形式。 這些軟件包使用算法。 一些軟件包如下所示 -
PorterStemmer包
這個Python包使用Porter算法來提取基礎表單。可以使用下面的Python代碼來這個包 -
from nltk.stem.porter import PorterStemmer例如,如果將writing這個詞作爲這個詞幹的輸入,它們就會在詞幹之後得到write這個詞。
LancasterStemmer包
這個Python包將使用Lancaster的算法來提取基本形式。 可以使用下面的Python代碼來導入這個包 -
from nltk.stem.lancaster import LancasterStemmer例如,如果將writing這個詞作爲這個詞幹的輸入,它們就會在詞幹之後得到write這個詞。
SnowballStemmer包
這個Python包將使用雪球算法來提取基本形式。 可以使用下面的Python代碼來導入這個包 -
from nltk.stem.snowball import SnowballStemmer例如,如果將writing這個詞作爲這個詞幹的輸入,它們就會在詞幹之後得到write這個詞。
所有這些算法都有不同程度的嚴格性。 如果比較這三個詞幹的話,那麼波特詞幹是最不嚴格的,蘭卡斯特詞幹是最嚴格的。 雪球詞幹在速度和嚴格性方面都很好用。
詞形還原
也可以通過詞形化來提取單詞的基本形式。 它基本上通過使用詞彙的詞彙和形態分析來完成這項任務,通常旨在僅刪除變元結尾。 任何單詞的這種基本形式都稱爲引理。
詞幹化和詞性化的主要區別在於詞彙的使用和形態分析。 另一個區別是,詞幹最常見的是崩潰派生相關的詞彙,而詞素化通常只會折攏引理的不同的折點形式。 例如,如果提供單詞saw作爲輸入詞,那麼詞幹可能會返回單詞's',但詞形化會嘗試返回單詞,看看或看到取決於使用該單詞是動詞還是名詞。
在Python NLTK模塊中,有以下與詞形化過程有關的包,可以使用它來獲取詞的基本形式 -
WordNetLemmatizer包
這個Python包將提取單詞的基本形式,取決於它是用作名詞還是動詞。 可以使用下面的Python代碼的來導入這個包 -
from nltk.stem import WordNetLemmatizer塊化:將數據分割成塊
它是自然語言處理中的重要過程之一。 分塊的主要工作是識別詞類和短語,如名詞短語。 我們已經研究了令牌化的過程,即令牌的創建。 分塊基本上就是這些令牌的標籤。 換句話說,組塊會告訴我們句子的結構。
在下面的章節中,我們將學習不同類型的分塊。
組塊的類型
有兩種類型的組塊。 類型如下 -
上分塊
在這個組塊過程中,對象,事物等向更普遍的方向發展,語言變得更加抽象。 有更多的協議機會。 在這個過程中縮小。 例如,如果將「汽車是爲了什麼目的」這個問題大肆渲染?我們可能會得到答案是:「運輸」。下分塊
在這個組塊過程中,對象,事物等朝着更具體的方向發展,語言更加滲透。 更深層次的結構將進行仔細檢查。 在這個過程中會放大。例如,如果將「專門講述一輛汽車」這個問題歸納起來? 會得到關於汽車的更小的信息。
示例
在這個例子中,我們將通過使用Python中的NLTK模塊來進行Noun-Phrase chunking,這是一種chunking類別,它可以在句子中找到名詞短語塊,
在python中執行這些步驟來實現名詞短語分塊 -
第1步 - 在這一步中,需要定義分塊的語法。 它將包含需要遵循的規則。
第2步 - 在這一步中,需要創建一個塊解析器。 它會解析語法並給出結果。
第3步 - 在最後一步中,輸出以樹格式生成。
按照以下步驟導入必要的NLTK包 -
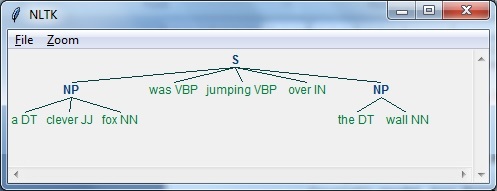
import nltk現在,我們需要定義這個句子。 這裏,DT表示行列式,VBP表示動詞,JJ表示形容詞,IN表示介詞,NN表示名詞。
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]現在,我們需要給出語法。 在這裏以正則表達式的形式給出語法。
grammar = "NP:{<DT>?<JJ>*<NN>}"我們需要定義一個解析器來解析語法。
parser_chunking = nltk.RegexpParser(grammar)解析器解析該句子如下 -
parser_chunking.parse(sentence)接下來,需要獲得輸出。 輸出在名爲output_chunk的變量中生成。
Output_chunk = parser_chunking.parse(sentence)執行以下代碼後,以樹的形式繪製輸出結果。
output.draw()執行上面代碼,得到以下結果 -
詞袋(BOW)模型
詞袋 - 英文爲:Bag of Word(BoW) ,它是自然語言處理中的一個模型,基本上用於從文本中提取特徵,以便文本可用於建模,以便在機器學習算法中使用。
現在問題出現了,爲什麼我們需要從文本中提取特徵。 這是因爲機器學習算法不能處理原始數據,他們需要數字數據,以便可以從中提取有意義的信息。 將文本數據轉換爲數字數據稱爲特徵提取或特徵編碼。
它是怎麼運行的
這是從文本中提取特徵的非常簡單的方法。 假設我們有一個文本文檔,並且希望將其轉換爲數字數據或者說想從中提取特徵,那麼首先這個模型從文檔中的所有單詞中提取詞彙。 然後通過使用文檔術語矩陣,它將建立一個模型。通過這種方式,BoW僅將文件表示爲一袋文字。 丟棄關於文檔中單詞的順序或結構的任何信息。
文檔術語矩陣的概念
BoW算法通過使用文檔術語矩陣來建立模型。 顧名思義,文檔術語矩陣就是文檔中出現的各種字數的矩陣。 在這個矩陣的幫助下,文本文檔可以表示爲各種單詞的加權組合。 通過設置閾值並選擇更有意義的單詞,我們可以構建文檔中可用作特徵向量的所有單詞的直方圖。 以下是瞭解文檔術語矩陣概念的示例 -
示例
假設有以下兩個句子 -
- 句子1 - 正在使用詞袋模型。
- 句子2 - Bag of Words模型用於提取特徵。
現在,通過考慮這兩句子,有以下13個不同的單詞 -
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
現在,我們需要使用每個句子中的單詞計數爲每個句子建立一個直方圖 -
- 子句1 − [1,1,1,1,1,1,1,1,0,0,0,0,0]
- 子句2 − [0,0,0,1,1,1,1,1,1,1,1,1,1]
這樣,就得到了已經提取的特徵向量。每個特徵向量都是13維的,因爲這裏有13個不同的單詞。
統計概念
統計學的概念稱爲TermFrequency-Inverse Document Frequency(tf-idf)。 每個單詞在文檔中都很重要。 統計數據有助於我們理解每個詞的重要性。
術語頻率(tf)
這是衡量每個單詞出現在文檔中的頻率。 它可以通過將每個詞的計數除以給定文檔中的詞的總數來獲得。
逆文檔頻率(idf)
這是衡量在給定的文檔集中這個文檔有多獨特的一個單詞。要計算idf和制定一個特徵向量,我們需要減少像這樣的常見詞的權重,並權衡稀有詞。
在NLTK中建立一個詞袋模型
在本節中,我們將使用CountVectorizer從這些句子中創建矢量來定義字符串集合。
導入必要的軟件包 -
from sklearn.feature_extraction.text import CountVectorizer現在定義一組句子。
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)上述程序生成如下所示的輸出。它表明在上述兩句話中有13個不同的單詞 -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}這些是可以用於機器學習的特徵向量(文本到數字形式)。
解決問題
在本節中,我們將解決一些相關問題。
類別預測
在一組文件中,不僅單詞而且單詞的類別也很重要; 在哪個類別的文本中特定的詞落入。 例如,想要預測給定的句子是否屬於電子郵件,新聞,體育,計算機等類別。在下面的示例中,我們將使用tf-idf來制定特徵向量來查找文檔的類別。使用sklearn的20個新聞組數據集中的數據。
導入必要的軟件包 -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer定義分類圖。使用五個不同的類別,分別是宗教,汽車,體育,電子和空間。
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}創建訓練集 -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)構建一個向量計數器並提取術語計數 -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)tf-idf轉換器的創建過程如下 -
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)現在,定義測試數據 -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]以上數據將用於訓練一個Multinomial樸素貝葉斯分類器 -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)使用計數向量化器轉換輸入數據 -
input_tc = vectorizer_count.transform(input_data)現在,將使用tfidf轉換器來轉換矢量化數據 -
input_tfidf = tfidf.transform(input_tc)執行上面代碼,將預測輸出類別 -
predictions = classifier.predict(input_tfidf)輸出結果如下 -
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])類別預測器生成以下輸出 -
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: Electronics性別發現器
在這個問題陳述中,將通過提供名字來訓練分類器以找到性別(男性或女性)。 我們需要使用啓發式構造特徵向量並訓練分類器。這裏使用scikit-learn軟件包中的標籤數據。 以下是構建性別查找器的Python代碼 -
導入必要的軟件包 -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import names現在需要從輸入字中提取最後的N個字母。 這些字母將作爲功能 -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':使用NLTK中提供的標籤名稱(男性和女性)創建培訓數據 -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)現在,測試數據將被創建如下 -
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']使用以下代碼定義用於列車和測試的樣本數 -
train_sample = int(0.8 * len(data))現在,需要迭代不同的長度,以便可以比較精度 -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)分類器的準確度可以計算如下 -
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')現在,可以預測輸出結果 -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i))上述程序將生成以下輸出 -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female在上面的輸出中可以看到,結束字母的最大數量的準確性是兩個,並且隨着結束字母數量的增加而減少。
主題建模:識別文本數據中的模式
我們知道,一般而言,文檔被分組爲主題。 有時需要確定文本中與特定主題相對應的模式。 這樣做的技術稱爲主題建模。 換句話說,可以說主題建模是一種揭示給定文檔集合中抽象主題或隱藏結構的技術。
可以在以下場景中使用主題建模技術 -
文本分類
在主題建模的幫助下,分類可以得到改進,因爲它將相似的單詞分組在一起,而不是分別將每個單詞用作特徵。
推薦系統
在主題建模的幫助下,可以使用相似性度量來構建推薦系統。
主題建模算法
主題建模可以通過使用算法來實現。 算法如下 -
潛在狄利克雷分配(LDA)
該算法是主題建模中最流行的算法。 它使用概率圖形模型來實現主題建模。 我們需要在Python中導入gensim包以使用LDA slgorithm。
潛在語義分析(LDA)或潛在語義索引(LSI)
該算法基於線性代數。 基本上它在文檔術語矩陣上使用SVD(奇異值分解)的概念。
非負矩陣分解(NMF)
它也基於線性代數。
上述所有用於話題建模的算法都將主題數量作爲參數,將文檔 - 詞彙矩陣作爲輸入,將WTM(詞主題矩陣)和TDM(主題文檔矩陣)作爲輸出。