人工智能機器學習
學習意味着通過學習或經驗獲得知識或技能。 基於此,我們可以定義機器學習(ML)如下 -
它被定義爲計算機科學領域,更具體地說是人工智能的應用,它提供計算機系統學習數據和改進經驗而不被明確編程的能力。
基本上,機器學習的主要重點是讓電腦自動學習,無需人工干預。 現在的問題是,如何開始這樣的學習並完成? 它可以從數據觀察開始。 數據可以是一些例子,指導或一些直接的經驗。 然後在這個輸入的基礎上,機器通過查找數據中的一些模式來做出更好的決定。
機器學習的類型(ML)
機器學習算法有助於計算機系統學習,而無需明確編程。 這些算法分爲有監督或無監督。 現在讓我們來看看幾個常見的算法 -
監督機器學習算法
這是最常用的機器學習算法。 它被稱爲監督學習算法,因爲從訓練數據集中算法學習的過程可以被認爲是監督學習過程的教師。 在這種ML算法中,可能的結果是已知的,並且訓練數據也標有正確的答案。可以理解如下 -
假設有輸入變量x和輸出變量y,並且我們應用了一種算法來學習從輸入到輸出的映射函數,例如 -
Y = f(x)現在,主要目標是近似映射函數,當有新的輸入數據(x)時,可以預測該數據的輸出變量(Y)。
主要監督問題可分爲以下兩類問題 -
- 分類 - 當有「黑色」,「教學」,「非教學」等分類輸出時,問題被稱爲分類問題。
- 迴歸 - 當擁有「距離」,「千克」等真實值輸出時,問題就稱爲迴歸問題。
決策樹,隨機森林,knn,邏輯迴歸是監督機器學習算法的例子。
顧名思義,這類機器學習算法沒有任何主管提供任何指導。 這就是爲什麼無監督機器學習算法與一些人們稱之爲真正的人工智能密切相關的原因。 可以理解如下 -
假設有輸入變量x,那麼在監督學習算法中就沒有相應的輸出變量。
簡而言之,可以說在無監督學習中,沒有正確的答案,也沒有教師指導。 算法有助於發現數據中有趣的模式。
無監督學習問題可以分爲以下兩類問題 -
- 聚類 - 在聚類問題中,我們需要發現數據中的固有分組。 例如,按顧客的購買行爲分組。
- 關聯 - 一個問題稱爲關聯問題,因爲這類問題需要發現描述大部分數據的規則。 例如,找到同時購買
x和y商品的顧客。
用於聚類的K-means,Apriori關聯算法是無監督機器學習算法的例子。
增強機器學習算法
這些機器學習算法的使用量非常少。 這些算法訓練系統做出特定的決定。 基本上,機器暴露在使用試錯法不斷訓練自己的環境中。 這些算法從過去的經驗中學習並嘗試捕獲最佳可能的知識以做出準確的決策。 馬爾可夫決策過程就是增強機器學習算法的一個例子。
最常見的機器學習算法
在本節中,我們將學習最常見的機器學習算法。 算法如下所述 -
線性迴歸
它是統計和機器學習中最着名的算法之一。
基本概念 - 主要是線性迴歸是一個線性模型,假設輸入變量x和單個輸出變量y之間的線性關係。 換句話說,y可以由輸入變量x的線性組合來計算。 變量之間的關係可以通過擬合最佳線來確定。
線性迴歸的類型
線性迴歸有以下兩種類型 -
- 簡單線性迴歸 - 如果線性迴歸算法只有一個獨立變量,則稱爲簡單線性迴歸。
- 多元線性迴歸 - 如果線性迴歸算法具有多個獨立變量,則稱其爲多元線性迴歸。
線性迴歸主要用於基於連續變量估計實際值。 例如,可以通過線性迴歸來估計一天內基於實際價值的商店總銷售額。
Logistic迴歸
它是一種分類算法,也稱爲logit迴歸。
主要邏輯迴歸是一種分類算法,用於根據給定的一組自變量來估計離散值,如0或1,真或假,是或否。 基本上,它預測的概率因此它的輸出在0和1之間。
決策樹
決策樹是一種監督學習算法,主要用於分類問題。
基本上它是一個基於自變量表示爲遞歸分區的分類器。 決策樹具有形成根樹的節點。 有根樹是一個帶有稱爲「根」節點的定向樹。 Root沒有任何傳入邊緣,所有其他節點都有一個傳入邊緣。 這些節點被稱爲樹葉或決策節點。 例如,考慮下面的決策樹來判斷一個人是否適合。
支持向量機(SVM)
它用於分類和迴歸問題。 但主要用於分類問題。 SVM的主要概念是將每個數據項繪製爲n維空間中的一個點,每個特徵的值是特定座標的值。 這裏n將是功能。 以下是瞭解SVM概念的簡單圖形表示 -
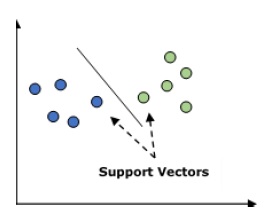
在上圖中,有兩個特徵,因此首先需要在二維空間中繪製這兩個變量,其中每個點都有兩個座標,稱爲支持向量。 該行將數據分成兩個不同的分類組。 這條線將是分類器。
樸素貝葉斯
這也是一種分類技術。 這種分類技術背後的邏輯是使用貝葉斯定理來構建分類器。 假設是預測變量是獨立的。 簡而言之,它假設類中某個特徵的存在與任何其他特徵的存在無關。 以下是貝葉斯定理的等式 -
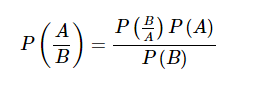
樸素貝葉斯模型易於構建,特別適用於大型數據集。
K-最近鄰居(KNN)
它用於問題的分類和迴歸。 它被廣泛用於解決分類問題。 該算法的主要概念是它用來存儲所有可用的案例,並通過其k個鄰居的多數選票來分類新案例。 然後將該情況分配給通過距離函數測量的K近鄰中最常見的類。 距離函數可以是歐幾里得,明可夫斯基和海明距離。 考慮以下使用KNN -
- 計算上KNN比用於分類問題的其他算法昂貴。
- 變量的規範化需要其他更高的範圍變量可以偏差。
- 在KNN中,需要在噪音消除等預處理階段進行工作。
K均值聚類
顧名思義,它用於解決聚類問題。 它基本上是一種無監督學習。 K-Means聚類算法的主要邏輯是通過許多聚類對數據集進行分類。 按照這些步驟通過K-means形成聚類 -
- K-means爲每個簇選取k個點,稱爲質心。
- 每個數據點形成具有最接近質心的羣集,即k個羣集。
- 它將根據現有集羣成員查找每個集羣的質心。
- 需要重複這些步驟直到收斂。
隨機森林
它是一個監督分類算法。 隨機森林算法的優點是它可以用於分類和迴歸兩類問題。 基本上它是決策樹的集合(即森林),或者可以說決策樹的集合。隨機森林的基本概念是每棵樹給出一個分類,並且森林從它們中選擇最好的分類。以下是隨機森林算法的優點 -
- 隨機森林分類器可用於分類和迴歸任務。
- 可以處理缺失的值。
- 即使在森林中有更多的樹,它也不會過度適合模型。