Pig & Hive介紹
在本教程中,我們將討論 Pig & Hive
Pig簡介
在Map Reduce框架,需要的程序將其轉化爲一系列 Map 和 Reduce階段。 但是,這不是一種編程模型,它被數據分析所熟悉。因此,爲了彌補這一差距,一個抽象概念叫 Pig 建立在 Hadoop 之上。
Pig是一種高級編程語言,分析大數據集非常有用。 Pig 是雅虎努力開發的結果
Pig 使人們能夠更專注於分析大量數據集和花更少的時間來寫map-reduce程序。
類似豬吃東西,Pig 編程語言的目的是可以在任何類型的數據工作。
Pig 由兩部分組成:
Pig Latin,這是一種語言
運行環境,用於運行PigLatin程序
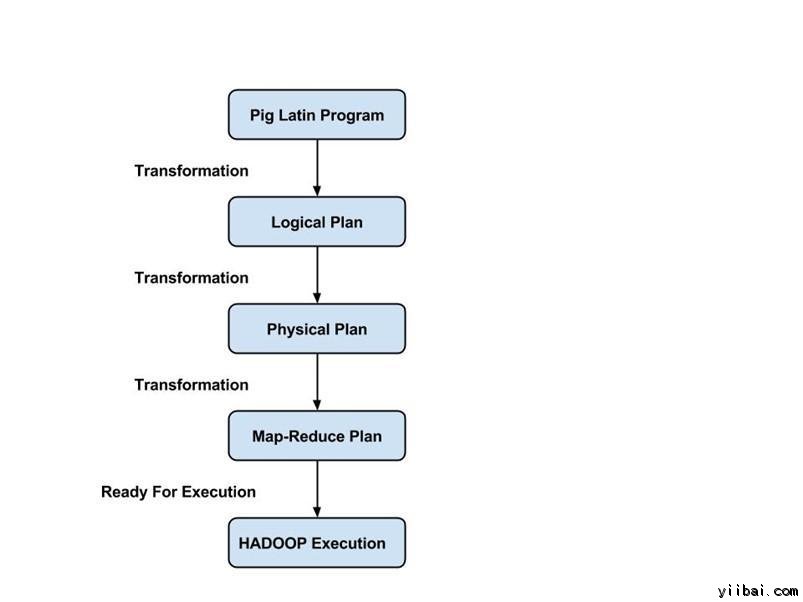
Pig Latin 程序由一系列操作或變換應用到輸入數據,以產生輸出。這些操作描述被翻譯成可執行到數據流,由 Pig 環境執行。下面,這些轉換的結果是一系列的 MapReduce 作業,程序員是不知道的。所以,在某種程度上,Pig 允許程序員關注數據,而不是執行過程。
Pig Latin 是一種相對硬挺的語言,它採用熟悉的關鍵字來處理數據,例如,Join, Group 和 Filter。
執行模式:
Pig 有兩種執行模式:
本機模式:在此模式下,Pig 運行在單個JVM,並使用本地文件系統。這種模式只適合使用 Pig 小數據集合分析。
Map Reduce模式:在此模式下,寫在 Pig Latin 的查詢被翻譯成MapReduce 作業,並 Hadoop 集羣上運行(集羣可能是僞或完全分佈式的)。 MapReduce 模式完全分佈式集羣對大型數據集運行 Pig 很有用的。
HIVE 介紹
在某種程度上數據集收集的大小並在行業用於商業智能分析正在增長,它使傳統的數據倉庫解決方案更加昂貴。HADOOP與MapReduce框架,被用於大型數據集分析的替代解決方案。雖然,Hadoop 地龐大的數據集上工作證明是非常有用的,MapReduce框架是非常低級別並且它需要程序員編寫自定義程序,這導致難以維護和重用。 Hive 就是爲程序員設計的。
Hive 演變爲基於Hadoop的Map-Reduce 框架之上的數據倉庫解決方案。
Hive 提供了類似於SQL的聲明性語言,叫作:HiveQL, 用於表達的查詢。使用 Hive-SQL,用戶能夠非常容易地進行數據分析。
Hive 引擎編譯這些查詢到 map-reduce作業中並在 Hadoop 上執行。此外,自定義 map-reduce 腳本,也可以插入查詢。Hive運行存儲在表中,它由基本數據類型,如數組和映射集合的數據類型的數據。
配置單元帶有一個命令行shell接口,可用於創建表並執行查詢。
Hive 查詢語言是類似於SQL,它支持子查詢。通過Hive查詢語言,可以使用 MapReduce 跨Hive 表連接。它有類似函數簡單的SQL支持- CONCAT, SUBSTR, ROUND 等等, 聚合函數 - SUM, COUNT, MAX etc。它還支持GROUP BY和SORT BY子句。 另外,也可以在配置單元查詢語言編寫用戶定義的功能。
MapReduce,Pig 和 Hive 的比較
Sqoop
Flume
HDFS
Sqoop用於從結構化數據源,例如,RDBMS導入數據
Flume 用於移動批量流數據到HDFS
HDFS使用 Hadoop 生態系統存儲數據的分佈式文件系統
Sqoop具有連接器的體系結構。連接器知道如何連接到相應的數據源並獲取數據
Flume 有一個基於代理的架構。這裏寫入代碼(這被稱爲「代理」),這需要處理取出數據
HDFS具有分佈式體系結構,數據被分佈在多個數據節點
HDFS 使用 Sqoop 將數據導出到目的地
通過零個或更多個通道將數據流給HDFS
HDFS是用於將數據存儲到最終目的地
Sqoop數據負載不事件驅動
Flume 數據負載可通過事件驅動
HDFS存儲通過任何方式提供給它的數據
爲了從結構化數據源導入數據,人們必須只使用Sqoop,因爲它的連接器知道如何與結構化數據源進行交互並從中獲取數據
爲了加載流數據,如微博產生的推文。或者登錄Web服務器的文件,Flume 應都可以使用。Flume 代理是專門爲獲取流數據而建立的。
HDFS擁有自己的內置shell命令將數據存儲。HDFS不能用於導入結構化或流數據