MapReduce簡介和入門
MapReduce 是適合海量數據處理的編程模型。Hadoop是能夠運行在使用各種語言編寫的MapReduce程序: Java, Ruby, Python, and C++. MapReduce程序是平行性的,因此可使用多臺機器集羣執行大規模的數據分析非常有用的。
MapReduce程序的工作分兩個階段進行:
Map階段
Reduce 階段
輸入到每一個階段均是鍵 - 值對。此外,每一個程序員需要指定兩個函數:map函數和reduce函數
整個過程要經歷三個階段執行,即
MapReduce如何工作
讓我們用一個例子來理解這一點 –
假設有以下的輸入數據到 MapReduce 程序,統計以下數據中的單詞數量:
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad
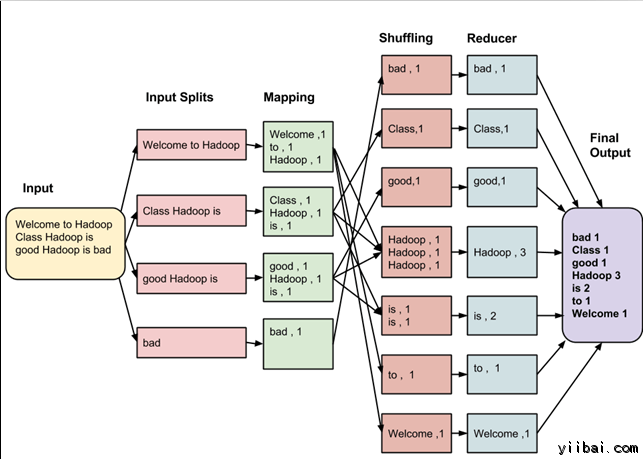
MapReduce 任務的最終輸出是:
bad
1
Class
1
good
1
Hadoop
3
is
2
to
1
Welcome
1
這些數據經過以下幾個階段
輸入拆分:
輸入到MapReduce工作被劃分成固定大小的塊叫做 input splits ,輸入折分是由單個映射消費輸入塊。
映射 - Mapping
這是在 map-reduce 程序執行的第一個階段。在這個階段中的每個分割的數據被傳遞給映射函數來產生輸出值。在我們的例子中,映射階段的任務是計算輸入分割出現每個單詞的數量(更多詳細信息有關輸入分割在下面給出)並編制以某一形式列表<單詞,出現頻率>
重排
這個階段消耗映射階段的輸出。它的任務是合併映射階段輸出的相關記錄。在我們的例子,同樣的詞彙以及它們各自出現頻率。
Reducing
在這一階段,從重排階段輸出值彙總。這個階段結合來自重排階段值,並返回一個輸出值。總之,這一階段彙總了完整的數據集。
在我們的例子中,這個階段彙總來自重排階段的值,計算每個單詞出現次數的總和。
詳細的整個過程
映射的任務是爲每個分割創建在分割每條記錄執行映射的函數。
有多個分割是好處的, 因爲處理一個分割使用的時間相比整個輸入的處理的時間要少, 當分割比較小時,處理負載平衡是比較好的,因爲我們正在並行地處理分割。
然而,也不希望分割的規模太小。當分割太小,管理分割和映射創建任務的超負荷開始逐步控制總的作業執行時間。
對於大多數作業,最好是分割成大小等於一個HDFS塊的大小(這是64 MB,默認情況下)。
map任務執行結果到輸出寫入到本地磁盤的各個節點上,而不是HDFS。
之所以選擇本地磁盤而不是HDFS是因爲,避免複製其中發生 HDFS 存儲操作。
映射輸出是由減少任務處理以產生最終的輸出中間輸出。
一旦任務完成,映射輸出可以扔掉了。所以,複製並將其存儲在HDFS變得大材小用。
在節點故障的映射輸出之前,由 reduce 任務消耗,Hadoop 重新運行另一個節點在映射上的任務,並重新創建的映射輸出。
減少任務不會在數據局部性的概念上工作。每個map任務的輸出被供給到 reduce 任務。映射輸出被傳輸至計算機,其中 reduce 任務正在運行。
在此機器輸出合併,然後傳遞到用戶定義的 reduce 函數。
不像到映射輸出,reduce輸出存儲在HDFS(第一個副本被存儲在本地節點上,其他副本被存儲於偏離機架的節點)。因此,寫入 reduce 輸出
MapReduce如何組織工作?
Hadoop 劃分工作爲任務。有兩種類型的任務:
Map 任務 (分割及映射)
Reduce 任務 (重排,還原)
如上所述
完整的執行流程(執行 Map 和 Reduce 任務)是由兩種類型的實體的控制,稱爲
Jobtracker : 就像一個主(負責提交的作業完全執行)
多任務跟蹤器 : 充當角色就像從機,它們每個執行工作
對於每一項工作提交執行在系統中,有一個 JobTracker 駐留在 Namenode 和 Datanode 駐留多個 TaskTracker。
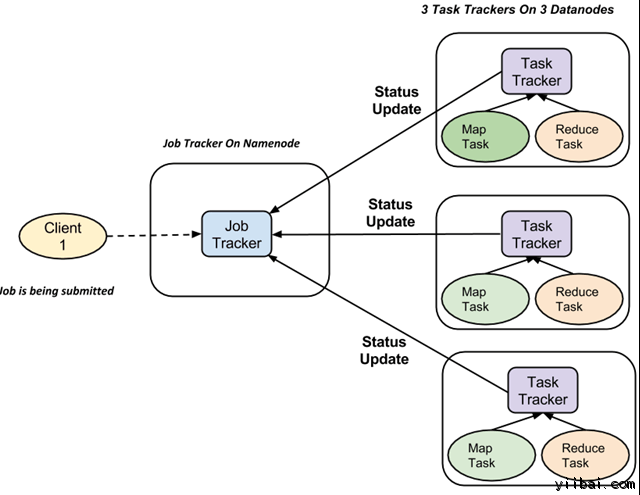
作業被分成多個任務,然後運行到集羣中的多個數據節點。
JobTracker的責任是協調活動調度任務來在不同的數據節點上運行。
單個任務的執行,然後由 TaskTracker 處理,它位於執行工作的一部分,在每個數據節點上。
TaskTracker 的責任是發送進度報告到JobTracker。
此外,TaskTracker 週期性地發送「心跳」信號信息給 JobTracker 以便通知系統它的當前狀態。
這樣 JobTracker 就可以跟蹤每項工作的總體進度。在任務失敗的情況下,JobTracker 可以在不同的 TaskTracker 重新調度它。