Hadoop程序入門實踐
問題陳述:
找出銷往各個國家商品數量。
輸入: 我們的畋輸入數據集合是一個 CSV 文件, Sales2014.csv
前提條件:
- 本教程是在Linux上開發 - Ubuntu操作系統
- 已經安裝了Hadoop(本教程使用版本2.7.1)
- 系統上已安裝了Java(本教程使用 JDK1.8.0)。
在實際操作過程中,使用的用戶是'hduser_「(此用戶使用 Hadoop)。
yiibai@ubuntu:~$ su hduser_
步驟:
1.創建一個新的目錄名稱是:MapReduceTutorial
hduser_@ubuntu:~$ sudo mkdir MapReduceTuorial
授予權限
hduser_@ubuntu:~$ sudo chmod -R 777 MapReduceTutorial
下載相關文件:下載 Java 程序文件,拷貝以下文件:SalesMapper.java, SalesCountryReducer.java 和 SalesCountryDriver.java 到 MapReduceTutorial 目錄中,
檢查所有這些文件的文件權限是否正確:
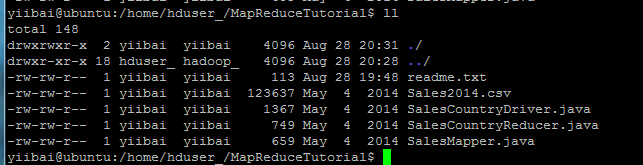
如果「讀取」權限缺少可重新再授予權限,執行以下命令:
yiibai@ubuntu:/home/hduser_/MapReduceTutorial$ sudo chmod +r *
2.導出類路徑
hduser_@ubuntu:/MapReduceTutorial$ export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.1.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.1.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.1.jar:/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"
hduser_@ubuntu:~/MapReduceTutorial$
3. 編譯Java文件(這些文件存在於目錄:Final-MapReduceHandsOn). 它的類文件將被放在包目錄:
hduser_@ubuntu:~/MapReduceTutorial$ javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java
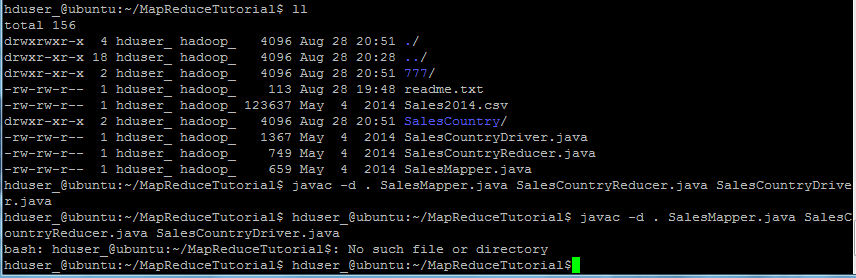
安全地忽略此警告:
此編譯將創建一個名稱與Java源文件(在我們的例子即,SalesCountry)指定包名稱的目錄,並把所有編譯的類文件在裏面,因此這個目錄要在編譯文件前創建。
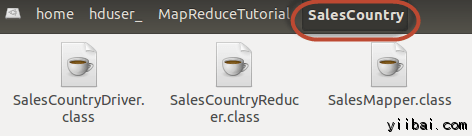
接下來:
創建一個新的文件:**Manifest.txt**
hduser_@ubuntu:~/MapReduceTutorial$ vi Manifest.txt
添加以下內容到文件中:
Main-Class: SalesCountry.SalesCountryDriver
SalesCountry.SalesCountryDriver 是主類的名稱。請注意,必須鍵入回車鍵,在該行的末尾。
下一步:創建一個 jar 文件
hduser_@ubuntu:~/MapReduceTutorial$ $JAVA_HOME/bin/jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class
檢查所創建的 jar 文件,結果如下:

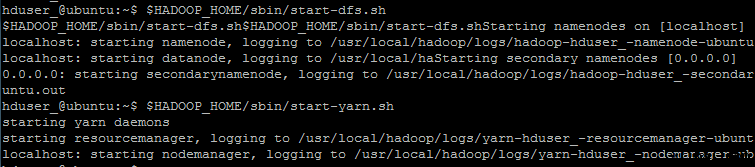
6. 啓動 Hadoop
hduser_@ubuntu:$ $HADOOP_HOME/sbin/start-dfs.sh$ $HADOOP_HOME/sbin/start-yarn.sh
hduser_@ubuntu:
7. 拷貝文件 Sales2014.csv 到 ~/inputMapReduce
hduser_@ubuntu:$ mkdir inputMapReduce$ cp MapReduceTutorial/Sales2014.csv ./inputMapReduce/Sales2014.csv
hduser_@ubuntu:
現在使用以下命令來拷貝 ~/inputMapReduce 到 HDFS.
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /
我們可以放心地忽略此警告。驗證文件是否真正複製沒有?
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce
8. 運行MapReduce 作業
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales
這將在 HDFS 上創建一個輸出目錄,名爲mapreduce_output_sales。此目錄的文件內容將包含每個國家的產品銷售。
9. 結果可以通過命令界面中可以看到
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
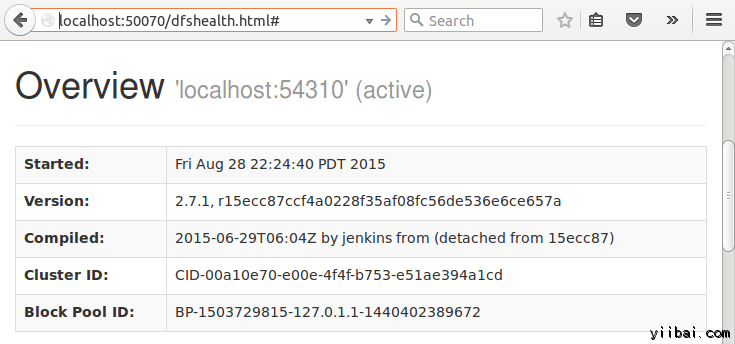
結果也可以通過 Web 界面看到,打開 Web 瀏覽器,輸入網址:http://localhost:50070/dfshealth.jsp ,結果如下:
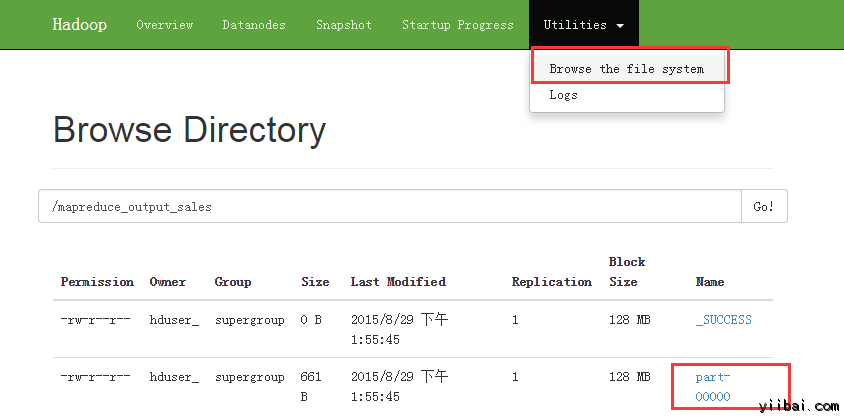
現在選擇 'Browse the filesystem' 並導航到 /mapreduce_output_sales 如下:
打開 part-r-00000 ,如下圖所示:
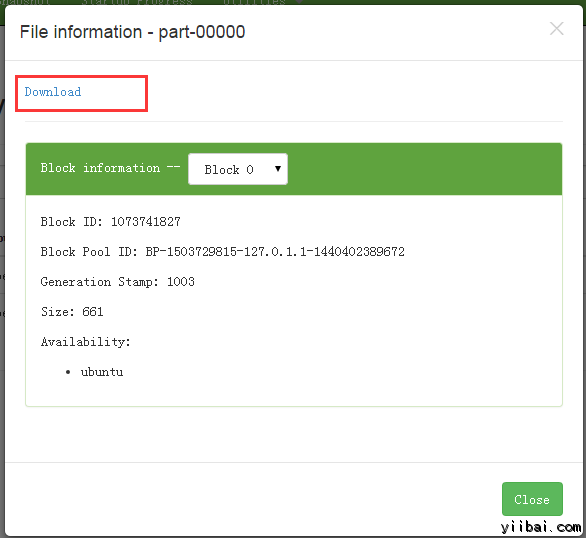
下載後,查看結果內容。