Hadoop MapReduce
MapReduce它可以編寫應用程序來處理海量數據,並行,大集羣的普通硬件,以可靠的方式的框架。
MapReduce是什麼?
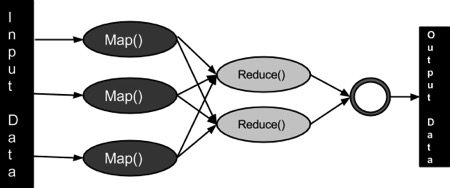
MapReduce是一種處理技術和程序模型基於Java的分佈式計算。 MapReduce算法包含了兩項重要任務,即Map 和 Reduce。Map採用了一組數據,並將其轉換成另一組數據,其中,各個元件被分解成元組(鍵/值對)。其次,減少任務,這需要從Map 作爲輸入並組合那些數據元組成的一組小的元組輸出。作爲MapReduce暗示的名稱的序列在Map作業之後執行reduce任務。
MapReduce主要優點是,它很容易大規模數據處理在多個計算節點。下面MapReduce模型中,數據處理的原語被稱爲映射器和減速器。分解數據處理應用到映射器和減速器有時是普通的。但是編寫MapReduce形式的應用,擴展應用程序運行在幾百,幾千,甚至幾萬機集羣中的僅僅是一個配置的更改。這個簡單的可擴展性是吸引了衆多程序員使用MapReduce模型。
算法
通常MapReduce範例是基於向發送計算機數據的位置!
MapReduce計劃分三個階段執行,即映射階段,shuffle階段,並減少階段。
映射階段:映射或映射器的工作是處理輸入數據。一般輸入數據是在文件或目錄的形式,並且被存儲在Hadoop的文件系統(HDFS)。輸入文件被傳遞到由線映射器功能線路。映射器處理該數據,並創建數據的若干小塊。
減少階段:這個階段是:Shuffle階段和Reduce階段的組合。減速器的工作是處理該來自映射器中的數據。處理之後,它產生一組新的輸出,這將被存儲在HDFS。
在一個MapReduce工作,Hadoop的發送Map和Reduce任務到集羣的相應服務器。
框架管理數據傳遞例如發出任務的所有節點之間的集羣周圍的詳細信息,驗證任務完成,和複製數據。
大部分的計算髮生在與在本地磁盤上,可以減少網絡通信量數據的節點。
給定的任務完成後,將羣集收集並減少了數據,以形成一個合適的結果,並且將其發送回Hadoop服務器。
輸入和輸出(Java透視圖)
MapReduce框架上的<key, value>對操作,也就是框架視圖的輸入工作作爲一組<key, value>對,併產生一組<key, value>對作爲作業的輸出可以在不同的類型。
鍵和值類在框架連載的方式,因此,需要實現接口。此外,鍵類必須實現可寫,可比的接口,以方便框架排序。MapReduce工作的輸入和輸出類型:(輸入)<k1, v1> ->映射 - ><k2, v2>-> reduce - ><k3, v3>(輸出)。
輸入
輸出
Map
<k1, v1>
list (<k2, v2>)
Reduce
<k2, list(v2)>
list (<k3, v3>)
術語
PayLoad - 應用程序實現映射和減少功能,形成工作的核心。
Mapper - 映射器的輸入鍵/值對映射到一組中間鍵/值對。
NamedNode - 節點管理Hadoop分佈式文件系統(HDFS)。
DataNode - 節點數據呈現在任何處理髮生之前。
MasterNode - 節點所在JobTracker運行並接受來自客戶端作業請求。
SlaveNode - 節點所在Map和Reduce程序運行。
JobTracker - 調度作業並跟蹤作業分配給任務跟蹤器。
Task Tracker - 跟蹤任務和報告狀態的JobTracker。
Job -程序在整個數據集映射器和減速的執行。
Task - 一個映射程序的執行或對數據的一個片段的減速器。
Task Attempt - 一種嘗試的特定實例在SlaveNode執行任務。
示例場景
下面給出是關於一個組織的電消耗量的數據。它包含了每月的用電量,各年的平均。
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
Avg
1979
23
23
2
43
24
25
26
26
26
26
25
26
25
1980
26
27
28
28
28
30
31
31
31
30
30
30
29
1981
31
32
32
32
33
34
35
36
36
34
34
34
34
1984
39
38
39
39
39
41
42
43
40
39
38
38
40
1985
38
39
39
39
39
41
41
41
00
40
39
39
45
如果上述數據作爲輸入,我們需要編寫應用程序來處理它而產生的結果,如發現最大使用量,最低使用年份,依此類推。這是一個輕鬆取勝用於記錄有限數目的編程器。他們將編寫簡單地邏輯,以產生所需的輸出,並且將數據傳遞到寫入的應用程序。
但是,代表一個特定狀態下所有的大規模產業的電力消耗數據。
當我們編寫應用程序來處理這樣的大量數據,
- 他們需要大量的時間來執行。
- 將會有一個很大的網絡流量,當我們將數據從源到網絡服務器等。
爲了解決這些問題,使用MapReduce框架。
輸入數據
上述數據被保存爲 sample.txt 並作爲輸入。輸入文件看起來如下所示。
1979 23 23 2 43 24 25 26 26 26 26 25 26 25 1980 26 27 28 28 28 30 31 31 31 30 30 30 29 1981 31 32 32 32 33 34 35 36 36 34 34 34 34 1984 39 38 39 39 39 41 42 43 40 39 38 38 40 1985 38 39 39 39 39 41 41 41 00 40 39 39 45
示例程序
下面給出的是使用MapReduce框架的樣本數據的程序。
package hadoop; import java.util.*; import java.io.IOException; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class ProcessUnits { //Mapper class public static class E_EMapper extends MapReduceBase implements Mapper<LongWritable ,/*Input key Type */ Text, /*Input value Type*/ Text, /*Output key Type*/ IntWritable> /*Output value Type*/ { //Map function public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); String lasttoken = null; StringTokenizer s = new StringTokenizer(line,"\t"); String year = s.nextToken(); while(s.hasMoreTokens()) { lasttoken=s.nextToken(); } int avgprice = Integer.parseInt(lasttoken); output.collect(new Text(year), new IntWritable(avgprice)); } } //Reducer class public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > { //Reduce function public void reduce( Text key, Iterator <IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int maxavg=30; int val=Integer.MIN_VALUE; while (values.hasNext()) { if((val=values.next().get())>maxavg) { output.collect(key, new IntWritable(val)); } } } } //Main function public static void main(String args[])throws Exception { JobConf conf = new JobConf(Eleunits.class); conf.setJobName("max_eletricityunits"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(E_EMapper.class); conf.setCombinerClass(E_EReduce.class); conf.setReducerClass(E_EReduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
保存上述程序作爲ProcessUnits.java。編譯和執行的程序如下的說明。
編譯和執行進程單位程序
讓我們假設是在Hadoop的用戶(如/home/hadoop)的主目錄。
按照下面給出編譯和執行上面程序的步驟。
第1步
下面的命令是創建一個目錄來存儲編譯的Java類。
$ mkdir units
第2步
下載Hadoop-core-1.2.1.jar,它用於編譯和執行MapReduce程序。訪問以下鏈接 http://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core/1.2.1下載JAR。假設下載的文件夾是 /home/hadoop/.
第3步
下面的命令用於編譯ProcessUnits.java程序並創建一個jar程序。
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .
第4步
下面的命令用來創建一個輸入目錄在HDFS中。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
第5步
下面的命令用於複製命名sample.txt在HDFS輸入目錄中輸入文件。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
第6步
下面的命令用來驗證在輸入目錄中的文件。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
第7步
下面的命令用於通過從輸入目錄以輸入文件來運行Eleunit_max應用。
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
等待一段時間,直到執行文件。在執行後,如下圖所示,輸出將包含輸入分割的數目,映射任務數,減速器任務的數量等。
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully 14/10/31 06:02:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=61 FILE: Number of bytes written=279400 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=546 HDFS: Number of bytes written=40 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=146137 Total time spent by all reduces in occupied slots (ms)=441 Total time spent by all map tasks (ms)=14613 Total time spent by all reduce tasks (ms)=44120 Total vcore-seconds taken by all map tasks=146137 Total vcore-seconds taken by all reduce tasks=44120 Total megabyte-seconds taken by all map tasks=149644288 Total megabyte-seconds taken by all reduce tasks=45178880 Map-Reduce Framework Map input records=5 Map output records=5 Map output bytes=45 Map output materialized bytes=67 Input split bytes=208 Combine input records=5 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=6 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=948 CPU time spent (ms)=5160 Physical memory (bytes) snapshot=47749120 Virtual memory (bytes) snapshot=2899349504 Total committed heap usage (bytes)=277684224 File Output Format Counters Bytes Written=40
第8步
下面的命令用來驗證在輸出文件夾所得文件。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
第9步
下面的命令是用來查看輸出Part-00000文件。該文件由HDFS產生。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
下面是由MapReduce的程序所產生的輸出。
1981 34 1984 40 1985 45
第10步
以下命令用於從HDFS輸出文件夾複製到本地文件系統進行分析。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop
重要命令
所有的Hadoop命令是由$HADOOP_HOME/bin/hadoop命令調用。不帶任何參數運行Hadoop腳本打印所有命令的描述。
Usage : hadoop [--config confdir] COMMAND
下表列出了可用的選項及其說明。
操作
描述
namenode -format
格式化DFS文件系統。
secondarynamenode
運行DFS二次名稱節點。
namenode
運行DFS名稱節點。
datanode
運行DFS的Datanode。
dfsadmin
運行DFS管理客戶端。
mradmin
運行映射,減少管理客戶端。
fsck
運行DFS文件系統檢查工具。
fs
運行一個通用的文件系統的用戶客戶端。
balancer
運行集羣平衡工具。
oiv
適用於離線FsImage查看器的fsimage。
fetchdt
從NameNode獲取團令牌。
jobtracker
運行MapReduce工作跟蹤節點。
pipes
運行管道的工作。
tasktracker
運行MapReduce任務跟蹤節點。
historyserver
運行作業歷史記錄服務器作爲一個獨立的守護進程。
job
操縱MapReduce工作。
queue
獲取有關作業隊列信息。
version
打印版本。
jar
運行一個jar文件。
distcp
複製文件或目錄的遞歸。
distcp2
DistCp第2版。
archive -archiveName NAME -p
創建一個Hadoop的歸檔。
classpath
打印需要得到Hadoop jar和所需要的庫的類路徑。
daemonlog
爲每個守護進程獲取/設置日誌級別
如何與MapReduce工作互動
Usage: hadoop job [GENERIC_OPTIONS]
以下是在一個Hadoop的作業可用通用選項。
GENERIC_OPTIONS
描述
-submit
提交作業。
status
打印映射,並減少完成的百分比以及所有的工作的計數器。
counter
打印的計數器值。
-kill
終止任務。
-events
打印接收到JobTracker爲給定範圍內的事件的詳細信息。
-history [all]
打印作業的詳細信息,未能終止提示詳細信息。有關作業的更多詳細信息,如每個任務取得成功的任務,任務可以嘗試通過指定[all]選項中查看。
-list[all]
顯示所有作業。-list 只顯示尚未完成的作業。
-kill-task
終止任務。終止任務不計入失敗的嘗試。
-fail-task
失敗的任務。失敗的任務都算對失敗的嘗試。
set-priority
更改作業的優先級。允許優先級值:VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW
要查看作業的狀態
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004
要查看作業歷史在output-dir
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/output
終止任務
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004